本文基于 golang 1.20.3
map 源码详见 github
结构
map 在 golang 运行时对应的结构是 hmap:
// A header for a Go map.
type hmap struct {
count int // # live cells == size of map.
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra
}以上看起来可能晦涩、难以理解,那我们就先来分析需要如何自行实现 map。
实现 map
map 通常被翻译成字典或者是映射,它表达了一种一对一的关系,即使用任意 key 通过 某种方式 可以获得对应的 value。
要实现 map 首先需要实现这个 某种方式。假定有一组 int 类型、不重复且有序的 key,例如 [0, 1, 2, 3],我们尝试使用简单的方式来实现:
- 定义一个数组存储 values
- 获取 key 对应的 value 时,通过计算
key % values.len获得一个值index - 使用
index从 values 数组中找到对应位置插入 value
以上取模即 key % values.len 就是前文描述的 某种方式,也就是映射函数,它实现了简单的 map。
但是有一个问题:上面的例子中,index 是均匀分布在 values 上,如果 map 是 [(0, v0), (1, v1), (2, v2), (3, v3), (4, v4)],那么 key 为 0 和 4 时,index 的值就都是 0 了(暂不考虑 values 数组扩容问题),这就是碰撞。
一个优秀的映射函数总是能将 key 尽量均匀的对应到一个 value,避免碰撞。以下是完美映射函数和不均匀的映射函数的对比:
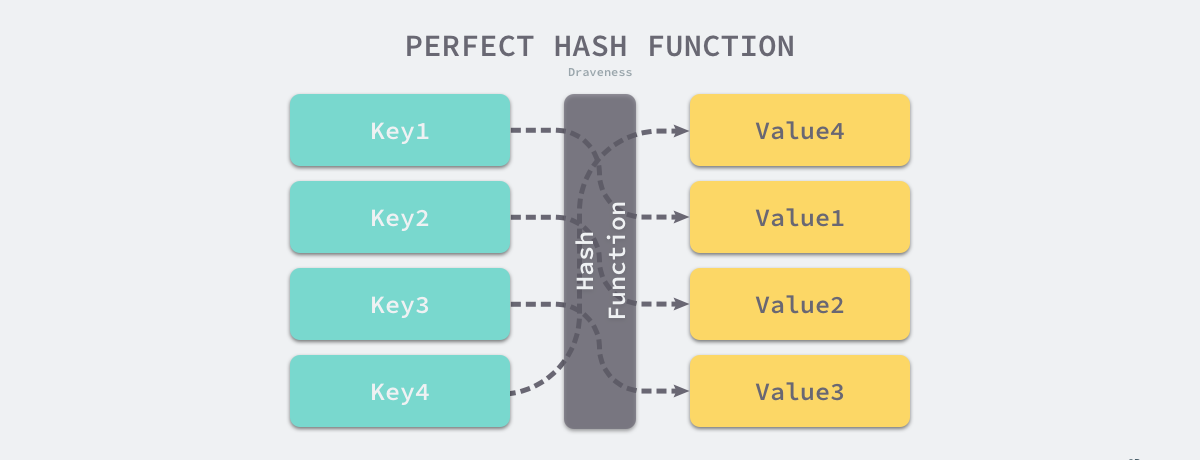
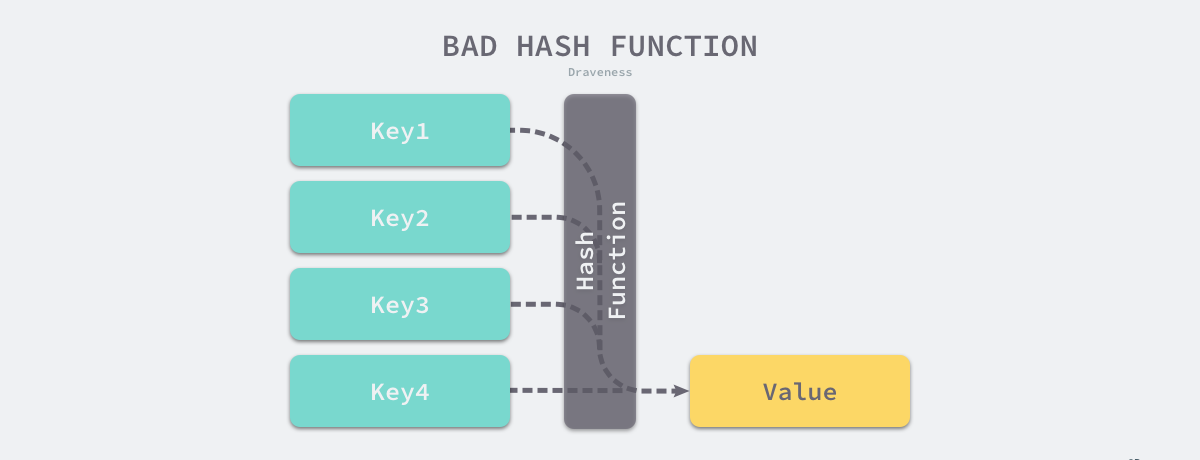
解决碰撞的方式有两种:
- 开放寻址法
- 拉链法
开放寻址法
当产生碰撞时依次往后检查,如果有空余的存储位就插入。以上面的例子就是:当计算 key 为 4 时计算出的 index 也为 0,此时访问 values[0] 发现已经存储了 value,依次往后访问到空位后插入。
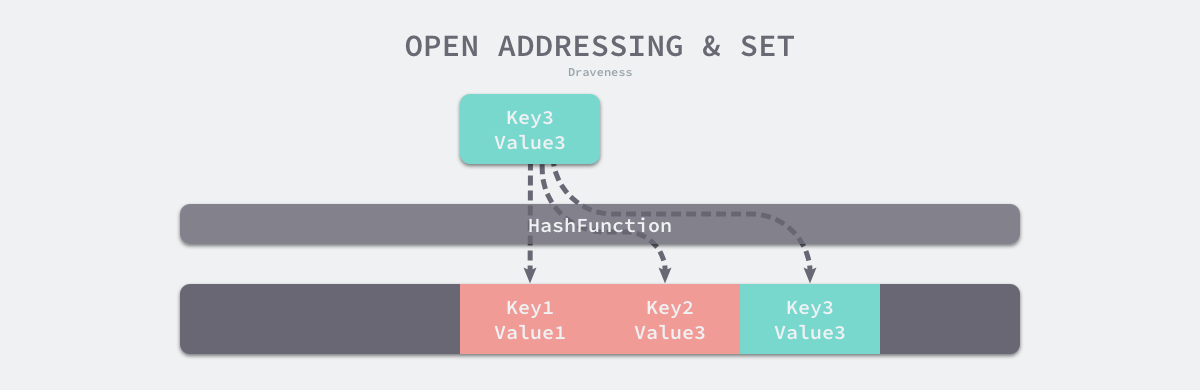
拉链法
拉链法和开放寻址法的不同之处在于处理碰撞的方式。拉链法一般会使用数组加链表,当产生碰撞时,在碰撞位连接上一条链表,并将碰撞元素插入链表中,访问时定位到位置后依次遍历链表来获取 value。
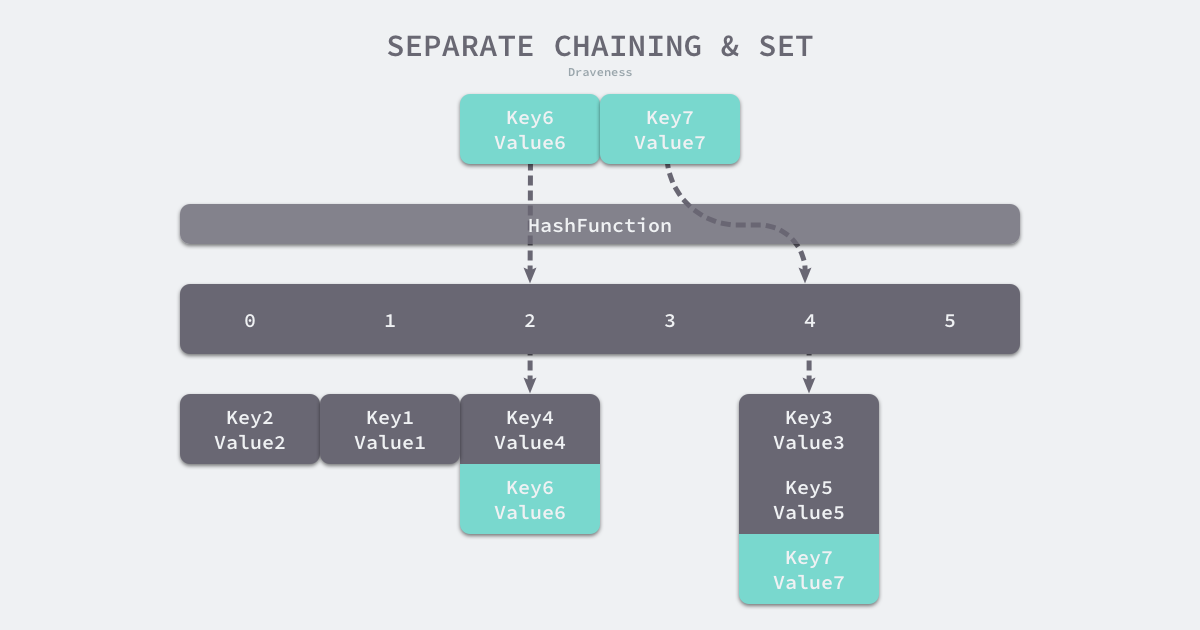
缺点
以上两种方法都有一定缺点。对于开放寻址法,当 map 存储至接近满容量时,可能会一直产生碰撞,最坏的情况下时间复杂度会有 退化至 ;对于拉链法,如果映射函数设计不良,map 可能会退化成一条链表。
评估以上两种方法性能的一个概念是装载因子,开放寻址法中的计算方式为元素数量与数组大小的比值,拉链法中为元素数量与桶数量的比值。装载因子越大,map 的性能越低。
回顾 struct
type hmap struct {
count int
flags uint8
B uint8
noverflow uint16
hash0 uint32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
nevacuate uintptr
extra *mapextra
}flag 为标记位置,iterator(1) 表示迭代器正在使用 buckets,oldIterator(10) 表示可能有迭代器在使用 oldbuckets,hashWriting(100) 表示一个协程正在写 map,sameSizeGrow(1000) 表示 map 当前的扩容方式是否是等量扩容,数字表示对应的 bit 位,定义如下:
const (
iterator = 1
oldIterator = 2
hashWriting = 4
sameSizeGrow = 8
)count 表示 map 中元素数量;B 表示桶以 为底的量,即实际桶数量为 ;hash0 为哈希种子,用于 map 的无序遍历,后续的源码中会见到这个属性。buckets 为桶数组的地址;oldbuckets 为溢出桶数组的地址;nevacuate 标记已迁移桶的地址;noverflow 表示当前溢出桶数。
TODO ;extra mapextra[1]
map 中的 bucket
(TODO 如果和xxx 一样,表示桶满了)
看了 map 的结构后,可能会 hmap 中的 bucket 相关结构会比较困惑,此处结合下图 hmap 结构简述

golang 中通过将开放寻址法和拉链法结合实现 map。
前文中开放寻址法中的数组对应着 buckets,当通过 hash 函数计算出了位置,就会从 buckets 中通过偏移定位到某个 bmap 结构,多个不同的 key/value 定位到同一个结构时,会从 extra.overflow 中拿出一个空 bmap 结构链接上,这里即是拉链法的思路。
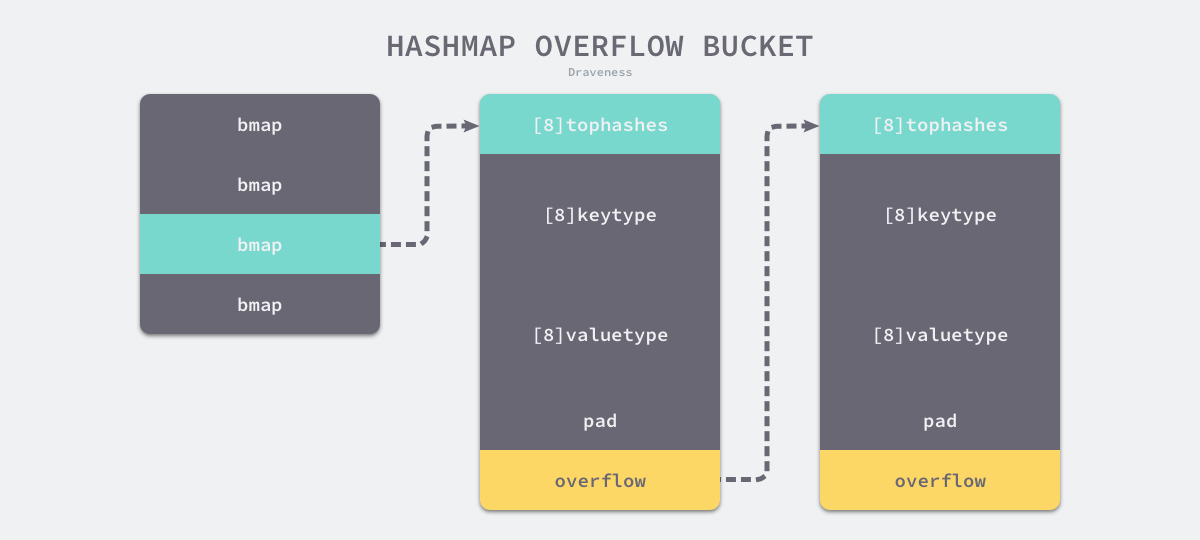
再看 bmap 的结构,存储了一个长度为 8 的 uint8 数组、8 个 key 数组和 value 数组,即一个 bmap 结构可以存储 1 个元素和 7 个冲突元素,topbits 会存储每个元素 hash 值的高位用于快速对比两个 key 是否相同。如果冲突持续产生,bmap 存满后会将 overflow 指向一个新的 bmap 地址,这样可以继续存储 8 对键值。
const (
// Maximum number of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
)
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
topbits [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
keys [bucketCnt]keytype
values [bucketCnt]valuetype
pad uintptr
overflow uintptr
}初始化
字面量创建
// 源码定义
hash := map[string]int{
"1": 2,
"3": 4,
"5": 6,
}形如此以上方式创建 map 会在编译期被 maplit 优化
func maplit(n *Node, m *Node, init *Nodes) {
a := nod(OMAKE, nil, nil)
a.Esc = n.Esc
a.List.Set2(typenod(n.Type), nodintconst(int64(n.List.Len())))
litas(m, a, init)
entries := n.List.Slice()
if len(entries) > 25 {
...
return
}
// Build list of var[c] = expr.
// Use temporaries so that mapassign1 can have addressable key, elem.
...
}根据其中的元素是否超过 25 为分界转换成不同形式:
// 元素未超过 25 时转换成以下形式
hash := make(map[string]int, 3)
hash["1"] = 2
hash["3"] = 4
hash["5"] = 6hash := make(map[string]int, 26)
vstatk := []string{"1", "2", "3", ... , "26"}
vstatv := []int{1, 2, 3, ... , 26}
for i := 0; i < len(vstak); i++ {
hash[vstatk[i]] = vstatv[i]
}Tip
vstatk 和 vstatv 会被编辑器继续展开
运行时
// walkMakeMap walks an OMAKEMAP node.
func walkMakeMap(n *ir.MakeExpr, init *ir.Nodes) ir.Node {
...
if ir.IsConst(hint, constant.Int) && constant.Compare(hint.Val(), token.LEQ, constant.MakeInt64(reflectdata.BUCKETSIZE)) {
// Handling make(map[any]any) and
// make(map[any]any, hint) where hint <= BUCKETSIZE
// special allows for faster map initialization and
// improves binary size by using calls with fewer arguments.
// For hint <= BUCKETSIZE overLoadFactor(hint, 0) is false
// and no buckets will be allocated by makemap. Therefore,
// no buckets need to be allocated in this code path.
if n.Esc() == ir.EscNone {
// Only need to initialize h.hash0 since
// hmap h has been allocated on the stack already.
// h.hash0 = rand32()
rand := mkcall("rand32", types.Types[types.TUINT32], init)
hashsym := hmapType.Field(4).Sym // hmap.hash0 see reflect.go:hmap
appendWalkStmt(init, ir.NewAssignStmt(base.Pos, ir.NewSelectorExpr(base.Pos, ir.ODOT, h, hashsym), rand))
return typecheck.ConvNop(h, t)
}
// Call runtime.makehmap to allocate an
// hmap on the heap and initialize hmap's hash0 field.
fn := typecheck.LookupRuntime("makemap_small", t.Key(), t.Elem())
return mkcall1(fn, n.Type(), init)
}
...
// When hint fits into int, use makemap instead of
// makemap64, which is faster and shorter on 32 bit platforms.
fnname := "makemap64"
argtype := types.Types[types.TINT64]
// Type checking guarantees that TIDEAL hint is positive and fits in an int.
// See checkmake call in TMAP case of OMAKE case in OpSwitch in typecheck1 function.
// The case of hint overflow when converting TUINT or TUINTPTR to TINT
// will be handled by the negative range checks in makemap during runtime.
if hint.Type().IsKind(types.TIDEAL) || hint.Type().Size() <= types.Types[types.TUINT].Size() {
fnname = "makemap"
argtype = types.Types[types.TINT]
}
fn := typecheck.LookupRuntime(fnname, hmapType, t.Key(), t.Elem())
return mkcall1(fn, n.Type(), init, reflectdata.MakeMapRType(base.Pos, n), typecheck.Conv(hint, argtype), h)
}字面量在编译时转换后,运行时 make(map) 会由 runtime.makemap/makemap_small[2] 执行,区别在于编译期会检查 map 需要的大小,未超过 reflectdata.BUCKETSIZE 则运行时执行 runtime.makemap_small 已追求更快的初始化速度。在 map 大小小于 reflectdata.BUCKETSIZE 的情况下,如果 map 未逃逸,则仅初始化随机数种子 hash0,hmap 已经在函数栈上初始化了;如果 map 逃逸了,则需要调用 makemap_small 在堆上初始化 map,后面我们详细看。当 map 初始容量超过 reflectdata.BUCKETSIZE 时,根据容量的类型,执行 makemap/makemap64
makemap_small
// makemap_small implements Go map creation for make(map[k]v) and
// make(map[k]v, hint) when hint is known to be at most bucketCnt
// at compile time and the map needs to be allocated on the heap.
func makemap_small() *hmap {
h := new(hmap)
h.hash0 = uint32(rand())
return h
}makemap_small 上的注释说的清晰,makemap_small 用于处理 make(map[k]v) 和 make(map[k]v, hint) 这两种类型的 map 的创建,不过需要 hint 至少超过 bucketCnt 并且需要分配在堆上。
makemap_small 实现很简单,new 一个 hmap 的指针,B 默认是 0,因为一个 bmap 可以保存 8 个元素
例如:
package main
func main() {
m := make(map[string]int, 3)
m["a"] = 1
m["b"] = 2
m["c"] = 2
}// TODO// TODO fmt.println(map) 会导致 map 逃逸
makemap
// makemap implements Go map creation for make(map[k]v, hint).
// If the compiler has determined that the map or the first bucket
// can be created on the stack, h and/or bucket may be non-nil.
// If h != nil, the map can be created directly in h.
// If h.buckets != nil, bucket pointed to can be used as the first bucket.
func makemap(t *maptype, hint int, h *hmap) *hmap {
mem, overflow := math.MulUintptr(uintptr(hint), t.Bucket.Size_)
if overflow || mem > maxAlloc {
hint = 0
}
// initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = uint32(rand())
// Find the size parameter B which will hold the requested # of elements.
// For hint < 0 overLoadFactor returns false since hint < bucketCnt.
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
// allocate initial hash table
// if B == 0, the buckets field is allocated lazily later (in mapassign)
// If hint is large zeroing this memory could take a while.
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
return h
}根据 hit 计算出 map 需要申请的内存大小,检测内存是否溢出或申请的内存超过限制
初始化 h 并引入随机种子[3]
默认桶容量为 1,元素需要超过一个桶容量(8)时计算 map 的装载因子(元素数量 / 桶数量),超过 6.5[4] 则将桶容量翻倍
如果 map 的桶数量超过 1 时,会在
makemap中立即分配内存,否则将在mapassign中分配通过
makeBucketArray[5] 分配内存:- 如果桶的数量超过 ,会增加一些额外 个溢出桶
- 通过
newarray创建桶数组 - 如果申请的同数量超过基础数量(即超过了 个桶),此时会将 hmap 中的
nextOverflow指针指向额外创建溢出桶的第一个,将最后一个溢出桶的溢出指针位设置成 hmap 的第一个桶。这样做可以避免跟踪溢出桶的开销,当nextOverflow的溢出桶指针为 nil,则可以继续偏移指针来追加溢出桶,否则说明溢出桶已经使用完毕
TIP
从
makeclear中调用makeBucketArray会传递dirtyalloc参数,此时在makeBucketArray中会使用该片已申请好的内存并初始化此时桶内存已经分配完成,将桶的地址设置到 hmap 上,如果在
makeBucketArray中生成溢出桶,则初始化 hmap 的 extra 字段,并设置nextOverflow
删除
map 的删除逻辑主要在运行时 mapdelete[6] 中
- 检查 map 是否在写入,有写入会直接终止程序
- 通过种子和 key 通过对应的类型的 hash 函数计算出 hash 值,并更新 flags 标记 map 正在写入
- 将 hash 和
1<<b-1执行与操作来获得 bucket 桶号- 如果 map 正在执行扩容,则对该 bucket 执行一次扩容迁移
- 将 bucket 序号和每个 bucket 的 size 相乘的结果从 map 桶起始地址做偏移,获得 bucket 序号桶的地址
- 获取 hash 的高八位值 top,如果 top 小于
minTopHash,则执行top+= minTopHash - 首先遍历该桶,如果该桶有溢出桶,则持续遍历溢出桶;对于每个桶,遍历其中的八个单元
- 如果当前单元的 tophash 值和 待查 key 的 tophash 不一致
- 如果当前单元为
emptyRest,表明后续都未空,则停止对此桶的继续搜索 - 如果当前单元不为
emptyRest,继续查询后续单元
- 如果当前单元为
- 当查找到 tophash 一致的单元,会通过
add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))从桶起始地址偏移 tophash 数组和未匹配的 keySize 来获得当前单元对应的 key 地址,如果 key 存的是间址,还会继续获取对应的地址 - 判断该单元 key 的值和所需删除的 key 是否一致,不一致则继续遍历下一个单元
- 查找到一致的单元后会将该单元的 tophash 设置成
emptyOne,接下来会执行一段逻辑处理emptyReset- 如果当前单元是该桶的最后一个元素,检查是否有溢出桶,如果有则检查溢出桶的首个单元的 tophash 不是
emptyReset则执行notLast逻辑 - 如果当前单元不是该桶的最后一个元素,且当前单元后一单元的 tophash 不是
emptyReset则执行notLast逻辑 notLast逻辑:如果溢出桶首个单元的 tophash 不是emptyReset则将 map 的 count 数减一,如果当前 map 已无元素(即 count 为 0),则重置 map 的 hash0(种子)- 如果当前单元是桶的最后一个单元,则执行设置
emptyReset的逻辑(Last 逻辑)- 从当前单元向低位循环设置 tophash 为
emptyReset,如果循环位不是 0(非桶起始位),则判断该位是否是emptyOne,如果是则继续更新为emptyReset,否则跳出循环 - 如果遍历位为桶的起始位,判断当前遍历的桶是否是删除元素的所在桶(非溢出桶),如果是,说明删除元素的所在桶(从原始桶至该桶的溢出桶)已全部处理完成,跳出循环
- 获取删除元素所在桶(可能为溢出桶)的前一个桶(可能为原始桶也可能为溢出桶),继续从第八位开始循环设置 tophash
- 从当前单元向低位循环设置 tophash 为
- 如果当前单元是该桶的最后一个元素,检查是否有溢出桶,如果有则检查溢出桶的首个单元的 tophash 不是
- 查找到一致的单元后会将该单元的 tophash 设置成
- 如果当前单元的 tophash 值和 待查 key 的 tophash 不一致
- 检查当前 map flags 的
hashWriting是否被取反,是则说明有其他协程正在写入,直接终止程序,否则清除写入位
TIP
// Like mapaccess, but allocates a slot for the key if it is not present in the map.
访问
计算 key 的 hash 值,通过和 B 位与计算出所在桶,遍历桶中的元素,如果有溢出桶,遍历溢出桶
编译阶段将词法、语法分析器生成的抽象语法树根据 op 不同转换成不同的运行时方法[7]
OINDEXMAP的节点(形如X[Index])根据是否是赋值语句转换[8]成mapassign和mapaccess1OAS2MAPR的节点(形如a, b = m[i])会转换[9]成mapaccess2
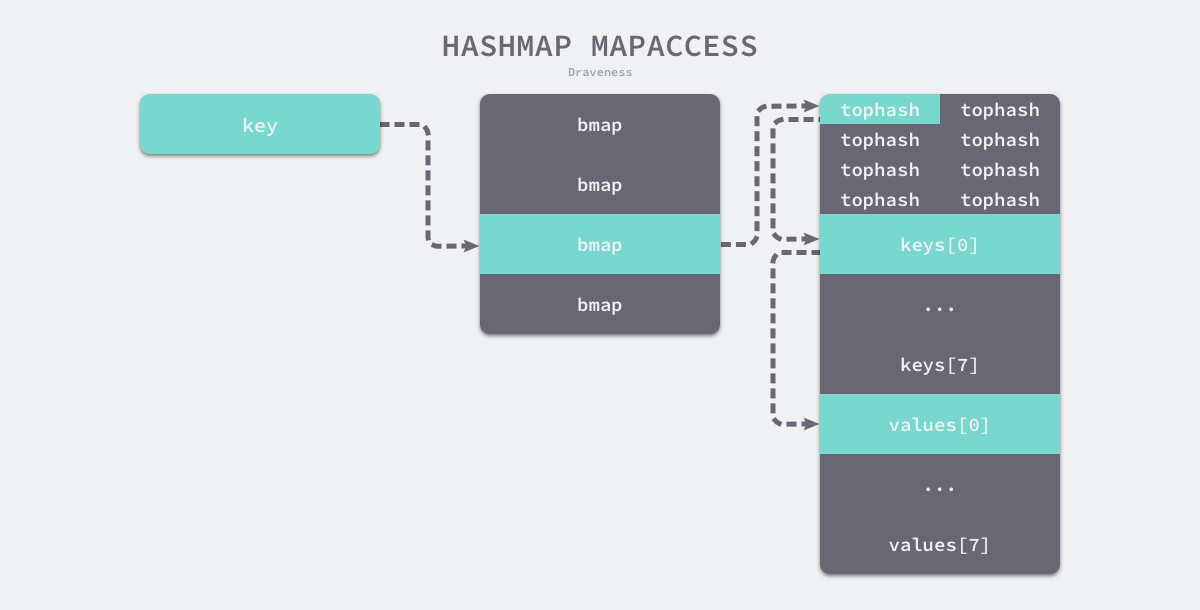
mapaccsee1/mapaccsee2
mapaccess1[10]mapaccess2[11]访问元素时首先检测 h.flags 的写入位,如果有协程写入时直接终止程序
- 计算 key 的 hash,并计算出 key 所在的正常桶编号,额外检查 map 的旧桶是否为空
- 如果 map 旧桶非空,则定位到当前 key 对应的旧桶位,检查旧桶位是否迁移,如果未迁移则从老桶中获取数据
- 遍历定位到桶的每个单元,如果 tophash 不一致且 tophash 的值为 emptyReset 则说明桶中无该 key,遍历桶的溢出桶(如果存在)继续判断
- 如果 tophash 一致,则对比单元中元素的 key 和所需的 key 是否一致,如果一致则返回元素的地址,否则返回 zeroVal
TIP
mapaccess1/2如果 key 不存在,不会返回nil,会返回一个元素类型零值的指针- 计算 key 的 hash,并计算出 key 所在的正常桶编号,额外检查 map 的旧桶是否为空
写入
在 访问 中可以知道,在赋值时会转为 mapassign[12] 方法
- 检查 map 是否在写入,有写入会直接终止程序
- 通过种子和 key 通过对应的类型的 hash 函数计算出 hash 值,并更新 flags 标记 map 正在写入
- 如果 bucket 为空则初始化 bucket(对应着运行时的处理中的逻辑,map 初始化阶段如无元素,则会在写入阶段初始化)
- 将 hash 和
1<<b-1执行与操作来获得 bucket 桶号- 如果 map 正在执行扩容,则对该 bucket 执行一次扩容迁移
- 将 bucket 序号和每个 bucket 的 size 相乘的结果从 map 桶起始地址做偏移,获得 bucket 序号桶的地址
- 获取 hash 的高八位值 top,如果 top 小于
minTopHash,则执行top+= minTopHash - 首先遍历该桶,如果该桶有溢出桶,则持续遍历溢出桶;对于每个桶,遍历其中的八个单元
- 如果当前单元的 tophash 值和 待查 key 的 tophash 不一致
- 如果当前单元为
emptyRest或者emptyOne并且尚未找到元素,则将当前单元地址标记为所查元素 - 如果当前单元为
emptyRest,表明后续都未空,则停止对此桶的继续搜索 - 如果当前单元不为
emptyRest,继续查询后续单元
- 如果当前单元为
- 当查找到 tophash 一致的单元,会通过
add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))从桶起始地址偏移 tophash 数组和未匹配的 keySize 来获得当前单元对应的 key 地址,如果 key 存的是间址,还会继续获取对应的地址,返回查询到的地址 - 遍历完所有后续溢出桶后,会执行一次扩容检查
- 如果遍历完后仍未找到对应 key,表示当前桶全部满了,且 key 不存在,需要申请在当前桶后继续链上新的溢出桶[16],并将新桶首地址作为查询到的地址返回
- count 增加 1
- 如果当前单元的 tophash 值和 待查 key 的 tophash 不一致
扩容
在触发扩容的方法 hashGrow[15:1] 中有一段注释:
INFO
If we’ve hit the load factor, get bigger. Otherwise, there are too many overflow buckets, so keep the same number of buckets and "grow" laterally.
说明有两种扩容方式
- 等量扩容
- 翻倍扩容
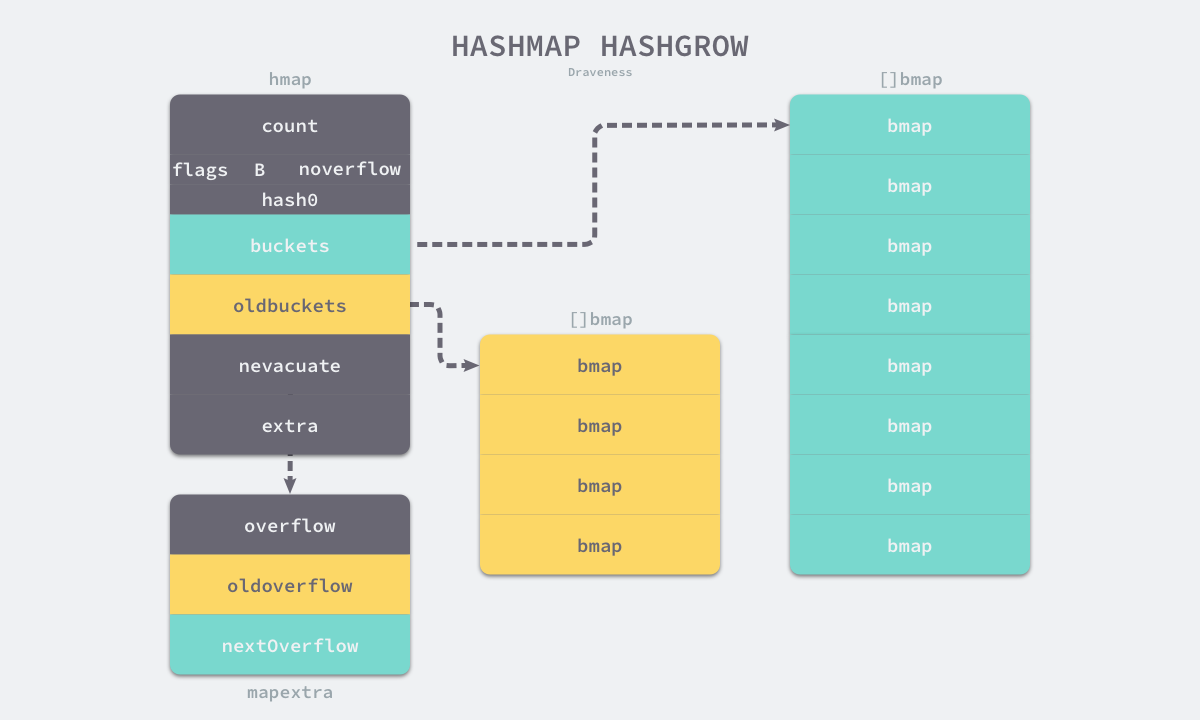
在 hashGrow 主要处理 hmap 的 flag、移动桶等工作,具体迁移的逻辑在方法 growWork 和 evacuate 中
- 计算当前 map 的元素数增加 1 后装载因子是否超过 6.5,未超过则将 flag 标记为等量扩容,否则则是增量扩容
- 将当前 map 桶放置到 oldbuckets 字段,如果当前在遍历 map 新桶或旧桶,一律标记遍历旧桶
- (这个操作需要考虑垃圾回收机制的影响,同时保证操作的原子性)修改 hmap 的 B、flags、oldbuckets、buckets 等,同时将 extra 中记录的溢出桶转移的 oldoverflow 字段,如果申请了新的溢出桶内存,也一并设置到
extra.nextOverflow上
每次调用 growWork[17] 时,会调用一次 evacuate[18] 对当前删除或写入桶对应的旧桶执行一次扩容搬迁,如果搬迁完仍未扩容完毕,则会额外执行一次扩容搬迁,不过两次搬迁的对象不同,一次是搬迁 oldbuckets 中的元素,;;;;我们来看 evacuate 内部的实现
通过偏移计算需要迁移的旧桶位置,盘点该桶是否迁移[19]
迁移是按照桶为单位,只要判断该桶的首个单元是否迁移即可,迁移过后单元的 tophash 根据扩容方式会被更新成
evacuatedX、evacuatedY、evacuatedEmpty中的一种,分别表示???如果不是这三种表示未迁移搬迁桶根据扩容方式的不同会采用两种方式:
- 等量扩容时会将旧桶中的元素迁移至 map 对应位置的新桶
- 翻倍扩容时会将旧桶中的元素分流迁移至 map 中对应两个位置新桶
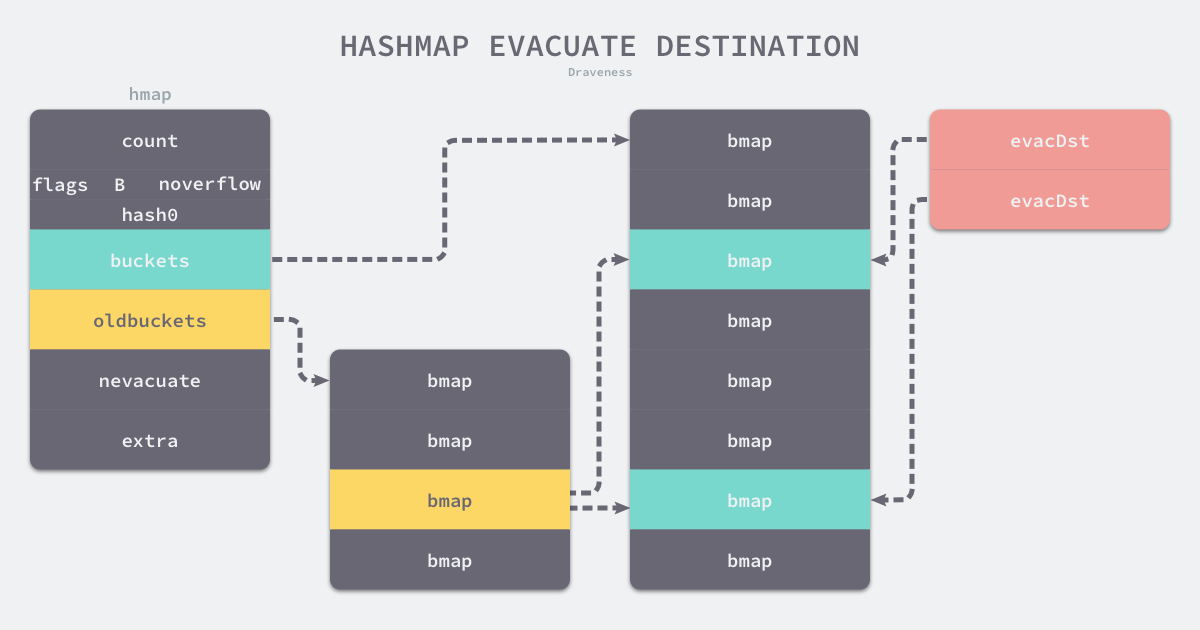
搬迁桶的过程中会使用
evacDst[20] 结构的、长度为 2 的数组xy,xy[0]用于记录 map 中对应旧桶的位置新桶,xy[1]在翻倍扩容时用于记录 map 中对应老桶新位置的新桶通过偏移计算
xy[0]的值,如果是翻倍扩容则计算xy[1]的值遍历旧桶及旧桶链接的所有溢出桶
遍历每个桶中的八个单元
如果当前单元的 tophash 是
emptyRest,则说明该单元无需搬迁,直接修改单元 tophash 为evacuatedEmpty如果当前单元有数据,则需要根据扩容方式来决定当前元素需要搬迁到的桶。如果是翻倍扩容,通过计算
hash&newbit来判断是否迁移到 map 的额外容量部分。确定之后表单元的 tophash 为evacuatedX或evacuatedY,并修改 buckets 中对应元素的 key、value、tophashTIP
newbit 是一个掩码,计算方式是将 1 左移旧桶对应的 B 数(
bucketShift),而计算 key 的 hash 在旧桶位置时使用的是bucketMask[21],所以当hash&newbit为 0 表示该 key 的 hash 无论是扩容前还是扩容后,计算的 bucket 都是一致的,因此如果hash&newbit非 0 时就迁移到扩容部分的新桶中当向 map 对应 oldbucket 相同位置的新桶或扩容部分对应的新桶插入第八个单元时,需要添加溢出桶,从 map 的扩容后新的溢出桶申请一个桶,继续迁移
遍历完成后,释放该旧桶的相关指针,辅助 GC
如果当前迁移完成的桶刚好是 map 中下一位待迁移的桶,更新
h.nevacuate- 将
h.nevacuate后移到下一个桶序号,遍历后续的桶是否已经搬迁过[22],如果全部搬迁过后将 map 对应的旧桶的引用删除,如果是等量扩容需要清除 flags
- 将
其它
- 快速随机数[3:1]
- bucketShift[23]
- t.hashMightPanic
- tophash
- newoverflow[16:1]
- incrnoverflow
- newoverflow
- createOverflow
- growing
- sameSizeGrow
- noldbuckets
- oldbucketmask
思考
makemap 参数中 h *hmap 哪来的,hit 是否是 cap
是否存在在扩容时 map 满了/需要新扩容
hashGrow
// commit the grow (atomic wrt gc)为什么要注意垃圾回收机制?hashGrow 中如何保证上次扩容结束了才扩容的?
搬迁过程中
if h.flags&iterator != 0 && !t.reflexivekey() && !t.key.equal(k2, k2) {是什么意思INFO
If key != key (NaNs), then the hash could be (and probably will be) entirely different from the old hash. Moreover, it isn’t reproducible. Reproducibility is required in the presence of iterators, as our evacuation decision must match whatever decision the iterator made. Fortunately, we have the freedom to send these keys eitherway. Also, tophash is meaningless for these kinds of keys. We let the low bit of tophash drive the evacuation decision. We recompute a new random tophash for the next level so these keys will get evenly distributed across all buckets after multiple grows.
map 只有在写入时才会发生扩容和迁移,并且在完全迁移后才会 gc 释放旧桶的内存。如果 map 写入不频繁,是否就会让 map 在一段时间内始终占用了两倍内存呢?
map 缩容?
Reference
- map 实践以及实现原理
- Go 语言设计与实现 哈希表
- map 缩容
- https://segmentfault.com/a/1190000022514909
- https://zhuanlan.zhihu.com/p/364904972
- https://zhuanlan.zhihu.com/p/271145056
- https://www.bilibili.com/video/BV1Sp4y1U7dJ
Codes
- mapextra ↩︎
- makemap ↩︎
- fastrand ↩︎ ↩︎
- overLoadFactor ↩︎
- makeBucketArray ↩︎
- mapdelete ↩︎
- walkExpr1 ↩︎
- walkIndexMap ↩︎
- walkAssignMapRead ↩︎
- mapaccess1 ↩︎
- mapaccess2 ↩︎
- mapassign ↩︎
- growing ↩︎
- tooManyOverflowBuckets ↩︎
- hashGrow ↩︎ ↩︎
- newoverflow ↩︎ ↩︎
- growWork ↩︎
- evacuate ↩︎
- evacuated ↩︎
- evacDst ↩︎
- bucketMask ↩︎
- bucketEvacuated ↩︎
- bucketShift ↩︎





