二进制文件是如何运行的
func funA() {
...
}
func main() {
go funA()
time.sleep(xxx)
}代码被构建成可执行文件后有执行入口,根据平台不同有 _rt0_amd64_linux[1]、_rt0_amd64_windows 等,该函数会执行一条汇编指令,调用 runtime.rt0_go 函数:
runtime.rt0_go[2] 包含了 Go 程序启动的大致流程:
- 调用
runtime·args暂存命令行参数用于后续解析 - 调用
runtime.osinit初始化系统核心数、物理页面大小等 - 调用
runtime·schedinit[3] 初始化调度系统 - 调用
runtime·newproc创建主协程 - 调用
runtime·mstart,当前线程进入调度循环
创建主协程
newproc[4] 旨在创建一个新的 g 并放入等待执行队列
- 在 g0 栈上生成 g
- 调用
runqput将 g 放到 p 的 runnext(当 currentG 执行完就会执行 runnext) 上- p 的本地队列未满时,将 g 放入协程 p 的本地队列
- 当
main已经执行,则唤醒该 g
newproc1[5] 旨在创建一个状态是 _Grunable 的 g
- 锁住 g 对应的 m,禁止 m 被抢占,因为在后续逻辑中可能会将 p 保存到局部变量中
- 调用
gfget获取空闲 g,如果未获取到则调用malg[6] 创建一个 g,分配栈空间,并添加到allgs中,调用casgstatusg 状态从_Gidle转为_GdeadTODO,并添加到[7]allg中 - 如果协程入口有参数如何处理 TODO
- 计算栈指针,并将程序及乎其设置为
goexit函数地址入口加上 1 指令大小[8],然后调用gostartcallfn,最终会调用gostartcall[9],在该函数中,将栈指针下移一位后并写入 pc 的值,这意味着在入栈了一个新的栈帧,原 pc 成为了返回地址,且新的 pc 被设置成协程函数入口。因此协程函数最终执行完后会返回到goexit并回收参数等资源,就仿佛是从goexit中调用了协程函数却没有执行一样 casgstatus更新 g 的状态为_GrunnablegcController.addScannableStack(pp, int64(newg.stack.hi-newg.stack.lo))TODO- 释放 m 的锁
gfget[10] 旨在获取一个空闲的 g
- 尝试获取关联 p 上空闲 g 队列 gFree
- 如果 p 上不存在空闲的 g 并且调度器全局 gFree 非空,则会将全局 gFree 中的空闲 g 弹出并设置到 p 上,直到 p 上的空闲 gFree 个数超过 32 个或者是全局空闲 gFree 已耗尽
- 清理该 g 已有的栈空间
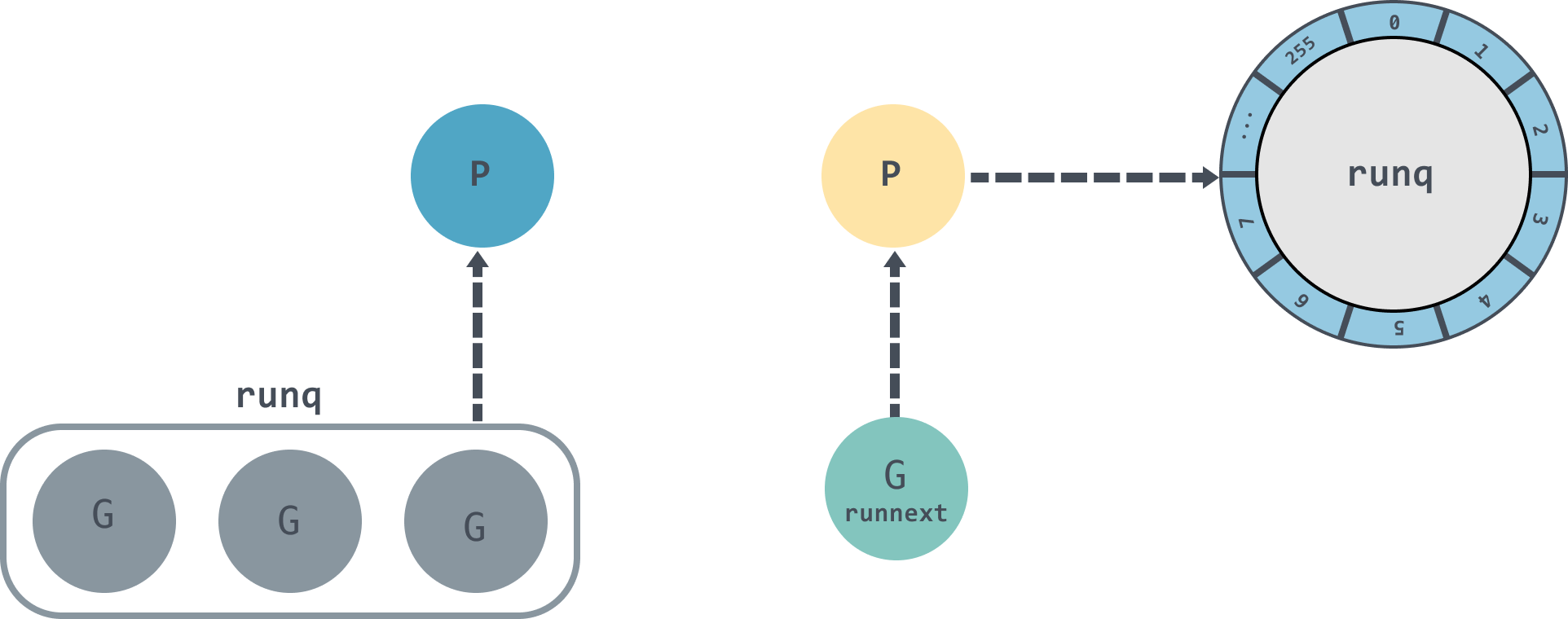
runqput[11] 旨在将 g 放到 p 的 runq 队列
- 当 next 为 true 会将 g 放到 runnext 上。如果 p 的 runnext 原本非空,则需要将该 g 从 runnext 放入 runq 尾部
- 当 next 为 false,会尝试将 g 放入 runq 的尾部
- 当 runq 未满时就放入 runq 中,否则调用
runqputslow放入全局 runq
runqputslow[12] 旨在将一个本地队列已满的 p 中的一半 g 和待添加 g 放入全局队列
- 验证 p 的本地队列已满
- 原子的获取 p 前一半本地队列的 g,获取失败可能是有 g 被消费了,直接返回 false 再次尝试放入 p 的本地队列
- 获取成功后将 g 依次链接并组成
gQueue后调用globrunqputbatch[13] 放入全局队列
启动 m
TEXT runtime·mstart(SB),NOSPLIT|TOPFRAME|NOFRAME,$0
CALL runtime·mstart0(SB)
RET // not reachedmstart 会调用 mstart0[14],最终会调用 mstart1[15],mstart1 初始化 m0,最后执行 schedule
调度 schedule
schedule[16] 每执行一次,就表示发生了一次调度
- 执行一些检测[17],例如:当前 m 是否持有锁(
newproc)、m 是否被 g 绑定(TODO) - 进入一个循环中[18],直到获取可执行的 g 并执行
- 首先获取当前 m 的 p 并设置
p.preempt为 false 禁止 p 被抢占(因为已经被调度到了,无需再抢占了) - 安全检查如果 m 处于自旋状态,p 不应有任何任何待执行的 g
- 调用
findRunnable获取一个可执行的 g 找到待执行的 ginheritTime(表示从p.runnext中窃取,则可以继承时间片,未继承时间片时说明执行了一次schedule,则p.schedtick会增加)tryWakeP表示找到的是特殊的 g(GC worker、tracereader 为什么特殊)TODO
- 获取到可执行 g 后原本自旋的 m 可以停止自旋
resetspinning sched.disable.user && !schedEnabled(gp)找到 g 后调度器检测是否允许调度用户协程,如果不允许则将该 g 放入调度器的 disable 队列暂存,并重新寻找可执行的 g,等到允许调度用户协程后,将 disable 队列中的 g 重新加入 runq 中tryWakeP为 true 就会调用wakeup[19] 唤醒 p 以保证有足够线程来调度 TraceReader 和 GC Worker TODOstartlockedm((如果 g 有绑定 m 则调用startlockedm[20] 唤醒对应绑定的 m 执行 g 且当前线程也要重新查找待执行的 g;如果 g 没有绑定的 m 则调用execute[21] 执行 TODO- 调用
execute执行 g
- 首先获取当前 m 的 p 并设置
findRunnable
Finds a runnable goroutine to execute.
Tries to steal from other P’s, get g from local or global queue, poll network.
tryWakePindicates that the returned goroutine is not normal (GC worker, trace reader) so the caller should try to wake a P.
findRunnable[22] 旨在会本地队列、全局队列、其他 p 的本地队列寻找一个可执行的 g,会阻塞到找到为止
- 检测
sched.gcwaiting,如果执行 gc 则调用gcstopm[23] 休眠当前 m - 执行安全点检查
runSafePointFn[24] checkTimers[25] 会运行当前 p 上所有已经达到触发时间的计时器now and pollUntil are saved for work stealing later, which may steal timers. It’s important that between now and then, nothing blocks, so these numbers remain mostly relevant.
- gcBlackenEnabled traceReader 这两种是非正常协程 TODO
- 为了公平[26],每调用
schedule函数 61 次就要调用globrunqget从全局可运行 G 队列中获取 1 个,保证效率的基础上兼顾公平性,防止本地队列上的两个持续唤醒的 goroutine 造成全局队列一直得不到调度 - 从本地队列获取 g
runqget[27] - 从全局 runq 中获取 g
globrunqget - 执行
netpull从网络 I/O 轮询器获取 glist,若返回值非空则将第一个 g 从列表中弹出,将剩余的尝试按本地 runq、全局 runq 的顺序插入 TODO - 判断 p 是否可以窃取其他 p 的 runq,需要满足两个条件[28]:当前 m 处于自旋等待或者出于自旋的 m 要小于处于工作中 p 的一半。这样是为了防止程序中 p 很大,但是并发性很低时,CPU 不必要的消耗
- 满足窃取 g 条件时[29],将 m 标记为自旋并调用
stealWork窃取 g - // gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker()
- 至此
findRunnable主要工作做完,会做一些额外工作[30]- 再次检测 gc 是否在等待执行,是则跳至 top 进行新的一轮
findRunnable,在新轮次的开始执行 gc - 再次从全局 runq 中获取 g
- 再次检测 gc 是否在等待执行,是则跳至 top 进行新的一轮
globrunqget
globrunqget[31] 旨在从全局 runq 队列中获取最多 max 个待执行的 g
- 首先调用
assertLockHeld[32] 保证调用者已经锁住调度器 - 计算得出最多能获取的 g 数量 n,g 的数量不能超过:max(非 0)、p 的 runq 一半
- 将首个可执行的 g 作为返回值,剩余的 n-1 个 g 放入 p 的 runq 中
stealWork
stealWork[33] 旨在从 timer 和其他 p 的 runq 中偷取 g
- 尝试窃取四次,前三次会从其他 p 的 runq 中窃取,最后一次会查找其他 p 的 timer[25:1]。
execute
execute[21:1] 会关联 m 和 g,将 g 设置成 _Grunning,并通过 gogo 函数将 g.sched 中的上下文恢复,最终调用 runtime·gogo[37] 恢复协程的上下文
抢占式调度
goexit[38] 中newproc1初始化 g 的上下文现场时会插入goexit1地址加一个指令,可以看到汇编函数中在call指令之前插入了 NOP 指令,并调用goexit1[39],最终调用goexit0。goexit0[40] 会将 g 状态置为_Gdead、清空属性、调用dropg将 g 与 m 解绑,调用gfput[41] 将 g 放入空闲队列,调用schedule执行调度
基于协作的抢占式调度
stacksplit编译期在函数调用前插入栈增长代码调用runtime.morestarck- 运行时会在 gc、系统监控检测发现 goroutine 执行时间超过 10ms 时发出抢占请求,将
g.stackguard0设置成stackPreempt - 协程发生函数调用时执行编译期插入的
runtime.morestack,它会调用runtime.newstack检测g.stackguard0,如果是stackPreempt则会触发抢占,调用gogo[37:1]
func fibonacci(n int) {
if n < 2 {
return 1
}
return fibonacci(n-1) + fibonacci(n-2)
}func fibonacci(n int) {
entry:
gp := getg()
if SP <= gp.stackguard0 {
goto morestack
}
return fibonacci(n-1) + fibonacci(n-2)
morestack:
runtime.morestack_noctxt()
go entry
}const (
uintptrMask = 1<<(8*goarch.PtrSize) - 1
// The values below can be stored to g.stackguard0 to force
// the next stack check to fail.
// These are all larger than any real SP.
// Goroutine preemption request.
// 0xfffffade in hex.
stackPreempt = uintptrMask & -1314
// Thread is forking. Causes a split stack check failure.
// 0xfffffb2e in hex.
stackFork = uintptrMask & -1234
// Force a stack movement. Used for debugging.
// 0xfffffeed in hex.
stackForceMove = uintptrMask & -275
// stackPoisonMin is the lowest allowed stack poison value.
stackPoisonMin = uintptrMask & -4096
)- stopTheWorldWithSema
- gcStart
- gcMarkDone
- stopTheWorld
基于信号的抢占式调度
- 程序启动时在
runtime.sighandler中注册SIGURG信号处理函数runtime.doSigPreempt - 触发 gc 的栈扫描时,调用
runtime.suspendG挂起 goroutine,同时将_Grunning状态的 goroutine 标记成可抢占,将preemptStop设置成 true,调用runtime.preemptM触发抢占 runtime.preemptM会调用runtime.signalM向线程发送信号SIGURG- 操作系统会中断正在运行的线程,并执行预先注册的信号处理函数
runtime.doSigPreempt处理抢占信号,获取当前 SP 和 PC 寄存器并调用runtime.sigctxt.pushCall runtime.sigctxt.pushCall会修改寄存器,并在程序回到用户态时执行runtime.asyncPreempt,汇编指令runtime.asyncPreempt会调用运行时函数runtime.asyncPreempt2,最后调用runtime.preemptParkruntime.preemptPark会将当前 goroutine 的状态修改到_Gpreempt,并调用runtime.schedule让当前函数陷入休眠并让出线程,调度器选择其他 goroutine 执行
结构
g
type g struct {
// Stack parameters.
// stack describes the actual stack memory: [stack.lo, stack.hi).
// stackguard0 is the stack pointer compared in the Go stack growth prologue.
// It is stack.lo+StackGuard normally, but can be StackPreempt to trigger a preemption.
// stackguard1 is the stack pointer compared in the C stack growth prologue.
// It is stack.lo+StackGuard on g0 and gsignal stacks.
// It is ~0 on other goroutine stacks, to trigger a call to morestackc (and crash).
stack stack // offset known to runtime/cgo
stackguard0 uintptr // offset known to liblink
stackguard1 uintptr // offset known to liblink
_panic *_panic // innermost panic - offset known to liblink
_defer *_defer // innermost defer
m *m // current m; offset known to arm liblink
sched gobuf
syscallsp uintptr // if status==Gsyscall, syscallsp = sched.sp to use during gc
syscallpc uintptr // if status==Gsyscall, syscallpc = sched.pc to use during gc
stktopsp uintptr // expected sp at top of stack, to check in traceback
// param is a generic pointer parameter field used to pass
// values in particular contexts where other storage for the
// parameter would be difficult to find. It is currently used
// in three ways:
// 1. When a channel operation wakes up a blocked goroutine, it sets param to
// point to the sudog of the completed blocking operation.
// 2. By gcAssistAlloc1 to signal back to its caller that the goroutine completed
// the GC cycle. It is unsafe to do so in any other way, because the goroutine's
// stack may have moved in the meantime.
// 3. By debugCallWrap to pass parameters to a new goroutine because allocating a
// closure in the runtime is forbidden.
param unsafe.Pointer
atomicstatus atomic.Uint32
stackLock uint32 // sigprof/scang lock; TODO: fold in to atomicstatus
goid uint64
schedlink guintptr
waitsince int64 // approx time when the g become blocked
waitreason waitReason // if status==Gwaiting
preempt bool // preemption signal, duplicates stackguard0 = stackpreempt
preemptStop bool // transition to _Gpreempted on preemption; otherwise, just deschedule
preemptShrink bool // shrink stack at synchronous safe point
// asyncSafePoint is set if g is stopped at an asynchronous
// safe point. This means there are frames on the stack
// without precise pointer information.
asyncSafePoint bool
paniconfault bool // panic (instead of crash) on unexpected fault address
gcscandone bool // g has scanned stack; protected by _Gscan bit in status
throwsplit bool // must not split stack
// activeStackChans indicates that there are unlocked channels
// pointing into this goroutine's stack. If true, stack
// copying needs to acquire channel locks to protect these
// areas of the stack.
activeStackChans bool
// parkingOnChan indicates that the goroutine is about to
// park on a chansend or chanrecv. Used to signal an unsafe point
// for stack shrinking.
parkingOnChan atomic.Bool
raceignore int8 // ignore race detection events
tracking bool // whether we're tracking this G for sched latency statistics
trackingSeq uint8 // used to decide whether to track this G
trackingStamp int64 // timestamp of when the G last started being tracked
runnableTime int64 // the amount of time spent runnable, cleared when running, only used when tracking
lockedm muintptr
sig uint32
writebuf []byte
sigcode0 uintptr
sigcode1 uintptr
sigpc uintptr
parentGoid uint64 // goid of goroutine that created this goroutine
gopc uintptr // pc of go statement that created this goroutine
ancestors *[]ancestorInfo // ancestor information goroutine(s) that created this goroutine (only used if debug.tracebackancestors)
startpc uintptr // pc of goroutine function
racectx uintptr
waiting *sudog // sudog structures this g is waiting on (that have a valid elem ptr); in lock order
cgoCtxt []uintptr // cgo traceback context
labels unsafe.Pointer // profiler labels
timer *timer // cached timer for time.Sleep
selectDone atomic.Uint32 // are we participating in a select and did someone win the race?
// goroutineProfiled indicates the status of this goroutine's stack for the
// current in-progress goroutine profile
goroutineProfiled goroutineProfileStateHolder
// Per-G tracer state.
trace gTraceState
// Per-G GC state
// gcAssistBytes is this G's GC assist credit in terms of
// bytes allocated. If this is positive, then the G has credit
// to allocate gcAssistBytes bytes without assisting. If this
// is negative, then the G must correct this by performing
// scan work. We track this in bytes to make it fast to update
// and check for debt in the malloc hot path. The assist ratio
// determines how this corresponds to scan work debt.
gcAssistBytes int64
}m
type m struct {
g0 *g // goroutine with scheduling stack
morebuf gobuf // gobuf arg to morestack
divmod uint32 // div/mod denominator for arm - known to liblink
_ uint32 // align next field to 8 bytes
// Fields not known to debuggers.
procid uint64 // for debuggers, but offset not hard-coded
gsignal *g // signal-handling g
goSigStack gsignalStack // Go-allocated signal handling stack
sigmask sigset // storage for saved signal mask
tls [tlsSlots]uintptr // thread-local storage (for x86 extern register)
mstartfn func()
curg *g // current running goroutine
caughtsig guintptr // goroutine running during fatal signal
p puintptr // attached p for executing go code (nil if not executing go code)
nextp puintptr
oldp puintptr // the p that was attached before executing a syscall
id int64
mallocing int32
throwing throwType
preemptoff string // if != "", keep curg running on this m
locks int32
dying int32
profilehz int32
spinning bool // m is out of work and is actively looking for work
blocked bool // m is blocked on a note
newSigstack bool // minit on C thread called sigaltstack
printlock int8
incgo bool // m is executing a cgo call
isextra bool // m is an extra m
isExtraInC bool // m is an extra m that is not executing Go code
freeWait atomic.Uint32 // Whether it is safe to free g0 and delete m (one of freeMRef, freeMStack, freeMWait)
fastrand uint64
needextram bool
traceback uint8
ncgocall uint64 // number of cgo calls in total
ncgo int32 // number of cgo calls currently in progress
cgoCallersUse atomic.Uint32 // if non-zero, cgoCallers in use temporarily
cgoCallers *cgoCallers // cgo traceback if crashing in cgo call
park note
alllink *m // on allm
schedlink muintptr
lockedg guintptr
createstack [32]uintptr // stack that created this thread.
lockedExt uint32 // tracking for external LockOSThread
lockedInt uint32 // tracking for internal lockOSThread
nextwaitm muintptr // next m waiting for lock
// wait* are used to carry arguments from gopark into park_m, because
// there's no stack to put them on. That is their sole purpose.
waitunlockf func(*g, unsafe.Pointer) bool
waitlock unsafe.Pointer
waitTraceBlockReason traceBlockReason
waitTraceSkip int
syscalltick uint32
freelink *m // on sched.freem
trace mTraceState
// these are here because they are too large to be on the stack
// of low-level NOSPLIT functions.
libcall libcall
libcallpc uintptr // for cpu profiler
libcallsp uintptr
libcallg guintptr
syscall libcall // stores syscall parameters on windows
vdsoSP uintptr // SP for traceback while in VDSO call (0 if not in call)
vdsoPC uintptr // PC for traceback while in VDSO call
// preemptGen counts the number of completed preemption
// signals. This is used to detect when a preemption is
// requested, but fails.
preemptGen atomic.Uint32
// Whether this is a pending preemption signal on this M.
signalPending atomic.Uint32
dlogPerM
mOS
// Up to 10 locks held by this m, maintained by the lock ranking code.
locksHeldLen int
locksHeld [10]heldLockInfo
}p
type p struct {
id int32
status uint32 // one of pidle/prunning/...
link puintptr
schedtick uint32 // incremented on every scheduler call
syscalltick uint32 // incremented on every system call
sysmontick sysmontick // last tick observed by sysmon
m muintptr // back-link to associated m (nil if idle)
mcache *mcache
pcache pageCache
raceprocctx uintptr
deferpool []*_defer // pool of available defer structs (see panic.go)
deferpoolbuf [32]*_defer
// Cache of goroutine ids, amortizes accesses to runtime·sched.goidgen.
goidcache uint64
goidcacheend uint64
// Queue of runnable goroutines. Accessed without lock.
runqhead uint32
runqtail uint32
runq [256]guintptr
// runnext, if non-nil, is a runnable G that was ready'd by
// the current G and should be run next instead of what's in
// runq if there's time remaining in the running G's time
// slice. It will inherit the time left in the current time
// slice. If a set of goroutines is locked in a
// communicate-and-wait pattern, this schedules that set as a
// unit and eliminates the (potentially large) scheduling
// latency that otherwise arises from adding the ready'd
// goroutines to the end of the run queue.
//
// Note that while other P's may atomically CAS this to zero,
// only the owner P can CAS it to a valid G.
runnext guintptr
// Available G's (status == Gdead)
gFree struct {
gList
n int32
}
sudogcache []*sudog
sudogbuf [128]*sudog
// Cache of mspan objects from the heap.
mspancache struct {
// We need an explicit length here because this field is used
// in allocation codepaths where write barriers are not allowed,
// and eliminating the write barrier/keeping it eliminated from
// slice updates is tricky, more so than just managing the length
// ourselves.
len int
buf [128]*mspan
}
// Cache of a single pinner object to reduce allocations from repeated
// pinner creation.
pinnerCache *pinner
trace pTraceState
palloc persistentAlloc // per-P to avoid mutex
// The when field of the first entry on the timer heap.
// This is 0 if the timer heap is empty.
timer0When atomic.Int64
// The earliest known nextwhen field of a timer with
// timerModifiedEarlier status. Because the timer may have been
// modified again, there need not be any timer with this value.
// This is 0 if there are no timerModifiedEarlier timers.
timerModifiedEarliest atomic.Int64
// Per-P GC state
gcAssistTime int64 // Nanoseconds in assistAlloc
gcFractionalMarkTime int64 // Nanoseconds in fractional mark worker (atomic)
// limiterEvent tracks events for the GC CPU limiter.
limiterEvent limiterEvent
// gcMarkWorkerMode is the mode for the next mark worker to run in.
// That is, this is used to communicate with the worker goroutine
// selected for immediate execution by
// gcController.findRunnableGCWorker. When scheduling other goroutines,
// this field must be set to gcMarkWorkerNotWorker.
gcMarkWorkerMode gcMarkWorkerMode
// gcMarkWorkerStartTime is the nanotime() at which the most recent
// mark worker started.
gcMarkWorkerStartTime int64
// gcw is this P's GC work buffer cache. The work buffer is
// filled by write barriers, drained by mutator assists, and
// disposed on certain GC state transitions.
gcw gcWork
// wbBuf is this P's GC write barrier buffer.
//
// TODO: Consider caching this in the running G.
wbBuf wbBuf
runSafePointFn uint32 // if 1, run sched.safePointFn at next safe point
// statsSeq is a counter indicating whether this P is currently
// writing any stats. Its value is even when not, odd when it is.
statsSeq atomic.Uint32
// Lock for timers. We normally access the timers while running
// on this P, but the scheduler can also do it from a different P.
timersLock mutex
// Actions to take at some time. This is used to implement the
// standard library's time package.
// Must hold timersLock to access.
timers []*timer
// Number of timers in P's heap.
numTimers atomic.Uint32
// Number of timerDeleted timers in P's heap.
deletedTimers atomic.Uint32
// Race context used while executing timer functions.
timerRaceCtx uintptr
// maxStackScanDelta accumulates the amount of stack space held by
// live goroutines (i.e. those eligible for stack scanning).
// Flushed to gcController.maxStackScan once maxStackScanSlack
// or -maxStackScanSlack is reached.
maxStackScanDelta int64
// gc-time statistics about current goroutines
// Note that this differs from maxStackScan in that this
// accumulates the actual stack observed to be used at GC time (hi - sp),
// not an instantaneous measure of the total stack size that might need
// to be scanned (hi - lo).
scannedStackSize uint64 // stack size of goroutines scanned by this P
scannedStacks uint64 // number of goroutines scanned by this P
// preempt is set to indicate that this P should be enter the
// scheduler ASAP (regardless of what G is running on it).
preempt bool
// pageTraceBuf is a buffer for writing out page allocation/free/scavenge traces.
//
// Used only if GOEXPERIMENT=pagetrace.
pageTraceBuf pageTraceBuf
// Padding is no longer needed. False sharing is now not a worry because p is large enough
// that its size class is an integer multiple of the cache line size (for any of our architectures).
}schedt
type schedt struct {
goidgen atomic.Uint64
lastpoll atomic.Int64 // time of last network poll, 0 if currently polling
pollUntil atomic.Int64 // time to which current poll is sleeping
lock mutex
// When increasing nmidle, nmidlelocked, nmsys, or nmfreed, be
// sure to call checkdead().
midle muintptr // idle m's waiting for work
nmidle int32 // number of idle m's waiting for work
nmidlelocked int32 // number of locked m's waiting for work
mnext int64 // number of m's that have been created and next M ID
maxmcount int32 // maximum number of m's allowed (or die)
nmsys int32 // number of system m's not counted for deadlock
nmfreed int64 // cumulative number of freed m's
ngsys atomic.Int32 // number of system goroutines
pidle puintptr // idle p's
npidle atomic.Int32
nmspinning atomic.Int32 // See "Worker thread parking/unparking" comment in proc.go.
needspinning atomic.Uint32 // See "Delicate dance" comment in proc.go. Boolean. Must hold sched.lock to set to 1.
// Global runnable queue.
runq gQueue
runqsize int32
// disable controls selective disabling of the scheduler.
//
// Use schedEnableUser to control this.
//
// disable is protected by sched.lock.
disable struct {
// user disables scheduling of user goroutines.
user bool
runnable gQueue // pending runnable Gs
n int32 // length of runnable
}
// Global cache of dead G's.
gFree struct {
lock mutex
stack gList // Gs with stacks
noStack gList // Gs without stacks
n int32
}
// Central cache of sudog structs.
sudoglock mutex
sudogcache *sudog
// Central pool of available defer structs.
deferlock mutex
deferpool *_defer
// freem is the list of m's waiting to be freed when their
// m.exited is set. Linked through m.freelink.
freem *m
gcwaiting atomic.Bool // gc is waiting to run
stopwait int32
stopnote note
sysmonwait atomic.Bool
sysmonnote note
// safepointFn should be called on each P at the next GC
// safepoint if p.runSafePointFn is set.
safePointFn func(*p)
safePointWait int32
safePointNote note
profilehz int32 // cpu profiling rate
procresizetime int64 // nanotime() of last change to gomaxprocs
totaltime int64 // ∫gomaxprocs dt up to procresizetime
// sysmonlock protects sysmon's actions on the runtime.
//
// Acquire and hold this mutex to block sysmon from interacting
// with the rest of the runtime.
sysmonlock mutex
// timeToRun is a distribution of scheduling latencies, defined
// as the sum of time a G spends in the _Grunnable state before
// it transitions to _Grunning.
timeToRun timeHistogram
// idleTime is the total CPU time Ps have "spent" idle.
//
// Reset on each GC cycle.
idleTime atomic.Int64
// totalMutexWaitTime is the sum of time goroutines have spent in _Gwaiting
// with a waitreason of the form waitReasonSync{RW,}Mutex{R,}Lock.
totalMutexWaitTime atomic.Int64
}var (
allm *m
gomaxprocs int32
ncpu int32
forcegc forcegcstate
sched schedt
newprocs int32
// allpLock protects P-less reads and size changes of allp, idlepMask,
// and timerpMask, and all writes to allp.
allpLock mutex
// len(allp) == gomaxprocs; may change at safe points, otherwise
// immutable.
allp []*p
// Bitmask of Ps in _Pidle list, one bit per P. Reads and writes must
// be atomic. Length may change at safe points.
//
// Each P must update only its own bit. In order to maintain
// consistency, a P going idle must the idle mask simultaneously with
// updates to the idle P list under the sched.lock, otherwise a racing
// pidleget may clear the mask before pidleput sets the mask,
// corrupting the bitmap.
//
// N.B., procresize takes ownership of all Ps in stopTheWorldWithSema.
idlepMask pMask
// Bitmask of Ps that may have a timer, one bit per P. Reads and writes
// must be atomic. Length may change at safe points.
timerpMask pMask
// Pool of GC parked background workers. Entries are type
// *gcBgMarkWorkerNode.
gcBgMarkWorkerPool lfstack
// Total number of gcBgMarkWorker goroutines. Protected by worldsema.
gcBgMarkWorkerCount int32
// Information about what cpu features are available.
// Packages outside the runtime should not use these
// as they are not an external api.
// Set on startup in asm_{386,amd64}.s
processorVersionInfo uint32
isIntel bool
goarm uint8 // set by cmd/link on arm systems
)调度器
- g
- m
- p
- runqhead uint32 无锁环形队列
- runqtail uint32
- runq [256]guintptr
相关函数
runtime.systemstack[^systemstack]TODO 该函数旨在临时性切换至当前 M 的 g0 栈,完成操作后再切换回原来的协程栈,主要用于执行触发栈增长函数。如果处于 gsignal??? 或 g0 栈上,则systemstack不会产生作用(当从 g0 切换回 g 后,会丢弃 g0 栈上的内容TODO)runtime.mcall[42] 和systemstack类似,但是不可以在 g0 栈上调用,也不会切换回 g。作用???将自己挂起runtime.gosave[^gosave]func handoffp(pp *p)
gcstopm
wakeup()
systemstack
// systemstack runs fn on a system stack.
// If systemstack is called from the per-OS-thread (g0) stack, or
// if systemstack is called from the signal handling (gsignal) stack,
// systemstack calls fn directly and returns.
// Otherwise, systemstack is being called from the limited stack
// of an ordinary goroutine. In this case, systemstack switches
// to the per-OS-thread stack, calls fn, and switches back.
// It is common to use a func literal as the argument, in order
// to share inputs and outputs with the code around the call
// to system stack:
//
// ... set up y ...
// systemstack(func() {
// x = bigcall(y)
// })
// ... use x ...
//
// func systemstack(fn func())
TEXT runtime·systemstack(SB), NOSPLIT, $0-8
MOVQ fn+0(FP), DI // DI = fn
get_tls(CX)
MOVQ g(CX), AX // AX = g
MOVQ g_m(AX), BX // BX = m
CMPQ AX, m_gsignal(BX)
JEQ noswitch
MOVQ m_g0(BX), DX // DX = g0
CMPQ AX, DX
JEQ noswitch
CMPQ AX, m_curg(BX)
JNE bad
// Switch stacks.
// The original frame pointer is stored in BP,
// which is useful for stack unwinding.
// Save our state in g->sched. Pretend to
// be systemstack_switch if the G stack is scanned.
CALL gosave_systemstack_switch<>(SB)
// switch to g0
MOVQ DX, g(CX)
MOVQ DX, R14 // set the g register
MOVQ (g_sched+gobuf_sp)(DX), SP
// call target function
MOVQ DI, DX
MOVQ 0(DI), DI
CALL DI
// switch back to g
get_tls(CX)
MOVQ g(CX), AX
MOVQ g_m(AX), BX
MOVQ m_curg(BX), AX
MOVQ AX, g(CX)
MOVQ (g_sched+gobuf_sp)(AX), SP
MOVQ (g_sched+gobuf_bp)(AX), BP
MOVQ $0, (g_sched+gobuf_sp)(AX)
MOVQ $0, (g_sched+gobuf_bp)(AX)
RET
noswitch:
// already on m stack; tail call the function
// Using a tail call here cleans up tracebacks since we won't stop
// at an intermediate systemstack.
MOVQ DI, DX
MOVQ 0(DI), DI
// The function epilogue is not called on a tail call.
// Pop BP from the stack to simulate it.
POPQ BP
JMP DI
bad:
// Bad: g is not gsignal, not g0, not curg. What is it?
MOVQ $runtime·badsystemstack(SB), AX
CALL AX
INT $3GMP
GM 模型
存在什么问题
- 全局 mutex 保护全局 runq,调度时要先获取锁,竞争严重
- G 的执行被分发到随机 M,造成在不同 M 频繁切换
GMP 模型
- 本地 runq 和全局 runq
- M 的自旋
Reference
- http://go.cyub.vip/index.html
- https://www.luozhiyun.com/archives/448
- https://blog.tianfeiyu.com/source-code-reading-notes/go/golang_gpm.html
- https://draveness.me/golang/
- 深度探索 Go 语言对象模型与 runtime 的原理、特性及应用
new main goroutine(newproc)
mstart -> schedule()
*runtime.main
sysmon, package init...
call main.main
....
*newproc(0, funA) -> newproc1(协程入口,参数地址,参数大小,父协程,返回地址)
...
acquirem() // 禁止当前 m 被抢占
...
gfget(_p_) // 获取空闲 g
如果无 g 则创建一个添加到 allgs
memmove // 协程入口如果有参数,将参数移动到协程栈上
runqput // 将 g 放到当前 p 的本地队列
...
releasem()
// 执行相关逻辑 funA
...
goexit() // 处理协程资源
exit()*gopark
acquirem
...
releasem
mcall(park_m)
*保存现场
switch g0 & it's stack
call runtime.park_m()
*
m.curg.m = nil
m.curg = nil
...
schedule()*runtime.goready
switch g0
runtime.ready()Codes
- ↩︎
TEXT _rt0_amd64(SB),NOSPLIT,$-8 MOVQ 0(SP), DI // argc LEAQ 8(SP), SI // argv JMP runtime·rt0_go(SB) - ↩︎
TEXT runtime·rt0_go(SB),NOSPLIT|TOPFRAME,$0 CALL runtime·check(SB) MOVL 24(SP), AX // copy argc MOVL AX, 0(SP) MOVQ 32(SP), AX // copy argv MOVQ AX, 8(SP) CALL runtime·args(SB) CALL runtime·osinit(SB) CALL runtime·schedinit(SB) // create a new goroutine to start program MOVQ $runtime·mainPC(SB), AX // entry PUSHQ AX CALL runtime·newproc(SB) POPQ AX // start this M CALL runtime·mstart(SB) CALL runtime·abort(SB) // mstart should never return RET - ↩︎
func schedinit() { gp := getg() ... sched.maxmcount = 10000 // The world starts stopped. worldStopped() moduledataverify() stackinit() mallocinit() godebug := getGodebugEarly() initPageTrace(godebug) // must run after mallocinit but before anything allocates cpuinit(godebug) // must run before alginit alginit() // maps, hash, fastrand must not be used before this call fastrandinit() // must run before mcommoninit mcommoninit(gp.m, -1) modulesinit() // provides activeModules typelinksinit() // uses maps, activeModules itabsinit() // uses activeModules stkobjinit() // must run before GC starts sigsave(&gp.m.sigmask) initSigmask = gp.m.sigmask goargs() goenvs() parsedebugvars() gcinit() lock(&sched.lock) sched.lastpoll.Store(nanotime()) procs := ncpu if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 { procs = n } if procresize(procs) != nil { throw("unknown runnable goroutine during bootstrap") } unlock(&sched.lock) // World is effectively started now, as P's can run. worldStarted() ... } - ↩︎
// Create a new g running fn. // Put it on the queue of g's waiting to run. // The compiler turns a go statement into a call to this. func newproc(fn *funcval) { gp := getg() pc := getcallerpc() systemstack(func() { newg := newproc1(fn, gp, pc) pp := getg().m.p.ptr() runqput(pp, newg, true) if mainStarted { wakep() } }) } - ↩︎
// Create a new g in state _Grunnable, starting at fn. callerpc is the // address of the go statement that created this. The caller is responsible // for adding the new g to the scheduler. func newproc1(fn *funcval, callergp *g, callerpc uintptr) *g { if fn == nil { fatal("go of nil func value") } mp := acquirem() // disable preemption because we hold M and P in local vars. pp := mp.p.ptr() newg := gfget(pp) if newg == nil { newg = malg(stackMin) casgstatus(newg, _Gidle, _Gdead) allgadd(newg) // publishes with a g->status of Gdead so GC scanner doesn't look at uninitialized stack. } if newg.stack.hi == 0 { throw("newproc1: newg missing stack") } if readgstatus(newg) != _Gdead { throw("newproc1: new g is not Gdead") } totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame totalSize = alignUp(totalSize, sys.StackAlign) sp := newg.stack.hi - totalSize spArg := sp if usesLR { // caller's LR *(*uintptr)(unsafe.Pointer(sp)) = 0 prepGoExitFrame(sp) spArg += sys.MinFrameSize } memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) newg.sched.sp = sp newg.stktopsp = sp newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function newg.sched.g = guintptr(unsafe.Pointer(newg)) gostartcallfn(&newg.sched, fn) newg.parentGoid = callergp.goid newg.gopc = callerpc newg.ancestors = saveAncestors(callergp) newg.startpc = fn.fn if isSystemGoroutine(newg, false) { sched.ngsys.Add(1) } else { // Only user goroutines inherit pprof labels. if mp.curg != nil { newg.labels = mp.curg.labels } if goroutineProfile.active { // A concurrent goroutine profile is running. It should include // exactly the set of goroutines that were alive when the goroutine // profiler first stopped the world. That does not include newg, so // mark it as not needing a profile before transitioning it from // _Gdead. newg.goroutineProfiled.Store(goroutineProfileSatisfied) } } // Track initial transition? newg.trackingSeq = uint8(fastrand()) if newg.trackingSeq%gTrackingPeriod == 0 { newg.tracking = true } casgstatus(newg, _Gdead, _Grunnable) gcController.addScannableStack(pp, int64(newg.stack.hi-newg.stack.lo)) if pp.goidcache == pp.goidcacheend { // Sched.goidgen is the last allocated id, // this batch must be [sched.goidgen+1, sched.goidgen+GoidCacheBatch]. // At startup sched.goidgen=0, so main goroutine receives goid=1. pp.goidcache = sched.goidgen.Add(_GoidCacheBatch) pp.goidcache -= _GoidCacheBatch - 1 pp.goidcacheend = pp.goidcache + _GoidCacheBatch } newg.goid = pp.goidcache pp.goidcache++ if raceenabled { newg.racectx = racegostart(callerpc) newg.raceignore = 0 if newg.labels != nil { // See note in proflabel.go on labelSync's role in synchronizing // with the reads in the signal handler. racereleasemergeg(newg, unsafe.Pointer(&labelSync)) } } if traceEnabled() { traceGoCreate(newg, newg.startpc) } releasem(mp) return newg } - ↩︎
// Allocate a new g, with a stack big enough for stacksize bytes. func malg(stacksize int32) *g { newg := new(g) if stacksize >= 0 { stacksize = round2(_StackSystem + stacksize) systemstack(func() { newg.stack = stackalloc(uint32(stacksize)) }) newg.stackguard0 = newg.stack.lo + _StackGuard newg.stackguard1 = ^uintptr(0) // Clear the bottom word of the stack. We record g // there on gsignal stack during VDSO on ARM and ARM64. *(*uintptr)(unsafe.Pointer(newg.stack.lo)) = 0 } return newg } - ↩︎
func allgadd(gp *g) { if readgstatus(gp) == _Gidle { throw("allgadd: bad status Gidle") } lock(&allglock) allgs = append(allgs, gp) if &allgs[0] != allgptr { atomicstorep(unsafe.Pointer(&allgptr), unsafe.Pointer(&allgs[0])) } atomic.Storeuintptr(&allglen, uintptr(len(allgs))) unlock(&allglock) } - ↩︎
totalSize := uintptr(4*goarch.PtrSize + sys.MinFrameSize) // extra space in case of reads slightly beyond frame totalSize = alignUp(totalSize, sys.StackAlign) sp := newg.stack.hi - totalSize spArg := sp if usesLR { // caller's LR *(*uintptr)(unsafe.Pointer(sp)) = 0 prepGoExitFrame(sp) spArg += sys.MinFrameSize } memclrNoHeapPointers(unsafe.Pointer(&newg.sched), unsafe.Sizeof(newg.sched)) newg.sched.sp = sp newg.stktopsp = sp newg.sched.pc = abi.FuncPCABI0(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function newg.sched.g = guintptr(unsafe.Pointer(newg)) gostartcallfn(&newg.sched, fn) newg.parentGoid = callergp.goid newg.gopc = callerpc newg.ancestors = saveAncestors(callergp) newg.startpc = fn.fn - ↩︎
// adjust Gobuf as if it executed a call to fn // and then stopped before the first instruction in fn. func gostartcallfn(gobuf *gobuf, fv *funcval) { var fn unsafe.Pointer if fv != nil { fn = unsafe.Pointer(fv.fn) } else { fn = unsafe.Pointer(abi.FuncPCABIInternal(nilfunc)) } gostartcall(gobuf, fn, unsafe.Pointer(fv)) } // adjust Gobuf as if it executed a call to fn with context ctxt // and then stopped before the first instruction in fn. func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) { sp := buf.sp sp -= goarch.PtrSize *(*uintptr)(unsafe.Pointer(sp)) = buf.pc buf.sp = sp buf.pc = uintptr(fn) buf.ctxt = ctxt } - ↩︎
// Get from gfree list. // If local list is empty, grab a batch from global list. func gfget(pp *p) *g { retry: if pp.gFree.empty() && (!sched.gFree.stack.empty() || !sched.gFree.noStack.empty()) { lock(&sched.gFree.lock) // Move a batch of free Gs to the P. for pp.gFree.n < 32 { // Prefer Gs with stacks. gp := sched.gFree.stack.pop() if gp == nil { gp = sched.gFree.noStack.pop() if gp == nil { break } } sched.gFree.n-- pp.gFree.push(gp) pp.gFree.n++ } unlock(&sched.gFree.lock) goto retry } gp := pp.gFree.pop() if gp == nil { return nil } pp.gFree.n-- if gp.stack.lo != 0 && gp.stack.hi-gp.stack.lo != uintptr(startingStackSize) { // Deallocate old stack. We kept it in gfput because it was the // right size when the goroutine was put on the free list, but // the right size has changed since then. systemstack(func() { stackfree(gp.stack) gp.stack.lo = 0 gp.stack.hi = 0 gp.stackguard0 = 0 }) } if gp.stack.lo == 0 { // Stack was deallocated in gfput or just above. Allocate a new one. systemstack(func() { gp.stack = stackalloc(startingStackSize) }) gp.stackguard0 = gp.stack.lo + _StackGuard } else { if raceenabled { racemalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo) } if msanenabled { msanmalloc(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo) } if asanenabled { asanunpoison(unsafe.Pointer(gp.stack.lo), gp.stack.hi-gp.stack.lo) } } return gp } - ↩︎
// runqput tries to put g on the local runnable queue. // If next is false, runqput adds g to the tail of the runnable queue. // If next is true, runqput puts g in the pp.runnext slot. // If the run queue is full, runnext puts g on the global queue. // Executed only by the owner P. func runqput(pp *p, gp *g, next bool) { if randomizeScheduler && next && fastrandn(2) == 0 { next = false } if next { retryNext: oldnext := pp.runnext if !pp.runnext.cas(oldnext, guintptr(unsafe.Pointer(gp))) { goto retryNext } if oldnext == 0 { return } // Kick the old runnext out to the regular run queue. gp = oldnext.ptr() } retry: h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with consumers t := pp.runqtail if t-h < uint32(len(pp.runq)) { pp.runq[t%uint32(len(pp.runq))].set(gp) atomic.StoreRel(&pp.runqtail, t+1) // store-release, makes the item available for consumption return } if runqputslow(pp, gp, h, t) { return } // the queue is not full, now the put above must succeed goto retry } - ↩︎
// Put g and a batch of work from local runnable queue on global queue. // Executed only by the owner P. func runqputslow(pp *p, gp *g, h, t uint32) bool { var batch [len(pp.runq)/2 + 1]*g // First, grab a batch from local queue. n := t - h n = n / 2 if n != uint32(len(pp.runq)/2) { throw("runqputslow: queue is not full") } for i := uint32(0); i < n; i++ { batch[i] = pp.runq[(h+i)%uint32(len(pp.runq))].ptr() } if !atomic.CasRel(&pp.runqhead, h, h+n) { // cas-release, commits consume return false } batch[n] = gp if randomizeScheduler { for i := uint32(1); i <= n; i++ { j := fastrandn(i + 1) batch[i], batch[j] = batch[j], batch[i] } } // Link the goroutines. for i := uint32(0); i < n; i++ { batch[i].schedlink.set(batch[i+1]) } var q gQueue q.head.set(batch[0]) q.tail.set(batch[n]) // Now put the batch on global queue. lock(&sched.lock) globrunqputbatch(&q, int32(n+1)) unlock(&sched.lock) return true } - ↩︎
func globrunqputbatch(batch *gQueue, n int32) { assertLockHeld(&sched.lock) sched.runq.pushBackAll(*batch) sched.runqsize += n *batch = gQueue{} } - ↩︎
// mstart0 is the Go entry-point for new Ms. // This must not split the stack because we may not even have stack // bounds set up yet. // // May run during STW (because it doesn't have a P yet), so write // barriers are not allowed. // //go:nosplit //go:nowritebarrierrec func mstart0() { gp := getg() osStack := gp.stack.lo == 0 if osStack { // Initialize stack bounds from system stack. // Cgo may have left stack size in stack.hi. // minit may update the stack bounds. // // Note: these bounds may not be very accurate. // We set hi to &size, but there are things above // it. The 1024 is supposed to compensate this, // but is somewhat arbitrary. size := gp.stack.hi if size == 0 { size = 8192 * sys.StackGuardMultiplier } gp.stack.hi = uintptr(noescape(unsafe.Pointer(&size))) gp.stack.lo = gp.stack.hi - size + 1024 } // Initialize stack guard so that we can start calling regular // Go code. gp.stackguard0 = gp.stack.lo + _StackGuard // This is the g0, so we can also call go:systemstack // functions, which check stackguard1. gp.stackguard1 = gp.stackguard0 mstart1() // Exit this thread. if mStackIsSystemAllocated() { // Windows, Solaris, illumos, Darwin, AIX and Plan 9 always system-allocate // the stack, but put it in gp.stack before mstart, // so the logic above hasn't set osStack yet. osStack = true } mexit(osStack) } - ↩︎
// The go:noinline is to guarantee the getcallerpc/getcallersp below are safe, // so that we can set up g0.sched to return to the call of mstart1 above. // //go:noinline func mstart1() { gp := getg() if gp != gp.m.g0 { throw("bad runtime·mstart") } // Set up m.g0.sched as a label returning to just // after the mstart1 call in mstart0 above, for use by goexit0 and mcall. // We're never coming back to mstart1 after we call schedule, // so other calls can reuse the current frame. // And goexit0 does a gogo that needs to return from mstart1 // and let mstart0 exit the thread. gp.sched.g = guintptr(unsafe.Pointer(gp)) gp.sched.pc = getcallerpc() gp.sched.sp = getcallersp() asminit() minit() // Install signal handlers; after minit so that minit can // prepare the thread to be able to handle the signals. if gp.m == &m0 { mstartm0() } if fn := gp.m.mstartfn; fn != nil { fn() } if gp.m != &m0 { acquirep(gp.m.nextp.ptr()) gp.m.nextp = 0 } schedule() } - ↩︎
/ One round of scheduler: find a runnable goroutine and execute it. // Never returns. func schedule() { mp := getg().m if mp.locks != 0 { throw("schedule: holding locks") } if mp.lockedg != 0 { stoplockedm() execute(mp.lockedg.ptr(), false) // Never returns. } // We should not schedule away from a g that is executing a cgo call, // since the cgo call is using the m's g0 stack. if mp.incgo { throw("schedule: in cgo") } top: pp := mp.p.ptr() pp.preempt = false // Safety check: if we are spinning, the run queue should be empty. // Check this before calling checkTimers, as that might call // goready to put a ready goroutine on the local run queue. if mp.spinning && (pp.runnext != 0 || pp.runqhead != pp.runqtail) { throw("schedule: spinning with local work") } gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available // This thread is going to run a goroutine and is not spinning anymore, // so if it was marked as spinning we need to reset it now and potentially // start a new spinning M. if mp.spinning { resetspinning() } if sched.disable.user && !schedEnabled(gp) { // Scheduling of this goroutine is disabled. Put it on // the list of pending runnable goroutines for when we // re-enable user scheduling and look again. lock(&sched.lock) if schedEnabled(gp) { // Something re-enabled scheduling while we // were acquiring the lock. unlock(&sched.lock) } else { sched.disable.runnable.pushBack(gp) sched.disable.n++ unlock(&sched.lock) goto top } } // If about to schedule a not-normal goroutine (a GCworker or tracereader), // wake a P if there is one. if tryWakeP { wakep() } if gp.lockedm != 0 { // Hands off own p to the locked m, // then blocks waiting for a new p. startlockedm(gp) goto top } execute(gp, inheritTime) } - ↩︎
mp := getg().m if mp.locks != 0 { throw("schedule: holding locks") } if mp.lockedg != 0 { stoplockedm() execute(mp.lockedg.ptr(), false) // Never returns. } // We should not schedule away from a g that is executing a cgo call, // since the cgo call is using the m's g0 stack. if mp.incgo { throw("schedule: in cgo") } - ↩︎
func schedule() { ... top: pp := mp.p.ptr() pp.preempt = false if mp.spinning && (pp.runnext != 0 || pp.runqhead != pp.runqtail) { throw("schedule: spinning with local work") } gp, inheritTime, tryWakeP := findRunnable() if mp.spinning { resetspinning() } if sched.disable.user && !schedEnabled(gp) { lock(&sched.lock) if schedEnabled(gp) { unlock(&sched.lock) } else { sched.disable.runnable.pushBack(gp) sched.disable.n++ unlock(&sched.lock) goto top } } if gp.lockedm != 0 { startlockedm(gp) goto top } execute(gp, inheritTime) } - ↩︎
// Tries to add one more P to execute G's. // Called when a G is made runnable (newproc, ready). // Must be called with a P. func wakep() { // Be conservative about spinning threads, only start one if none exist // already. if sched.nmspinning.Load() != 0 || !sched.nmspinning.CompareAndSwap(0, 1) { return } // Disable preemption until ownership of pp transfers to the next M in // startm. Otherwise preemption here would leave pp stuck waiting to // enter _Pgcstop. // // See preemption comment on acquirem in startm for more details. mp := acquirem() var pp *p lock(&sched.lock) pp, _ = pidlegetSpinning(0) if pp == nil { if sched.nmspinning.Add(-1) < 0 { throw("wakep: negative nmspinning") } unlock(&sched.lock) releasem(mp) return } // Since we always have a P, the race in the "No M is available" // comment in startm doesn't apply during the small window between the // unlock here and lock in startm. A checkdead in between will always // see at least one running M (ours). unlock(&sched.lock) startm(pp, true, false) releasem(mp) } - ↩︎
// Schedules the locked m to run the locked gp. // May run during STW, so write barriers are not allowed. // //go:nowritebarrierrec func startlockedm(gp *g) { mp := gp.lockedm.ptr() if mp == getg().m { throw("startlockedm: locked to me") } if mp.nextp != 0 { throw("startlockedm: m has p") } // directly handoff current P to the locked m incidlelocked(-1) pp := releasep() mp.nextp.set(pp) notewakeup(&mp.park) stopm() } - ↩︎ ↩︎
// Schedules gp to run on the current M. // If inheritTime is true, gp inherits the remaining time in the // current time slice. Otherwise, it starts a new time slice. // Never returns. // // Write barriers are allowed because this is called immediately after // acquiring a P in several places. // //go:yeswritebarrierrec func execute(gp *g, inheritTime bool) { mp := getg().m if goroutineProfile.active { // Make sure that gp has had its stack written out to the goroutine // profile, exactly as it was when the goroutine profiler first stopped // the world. tryRecordGoroutineProfile(gp, osyield) } // Assign gp.m before entering _Grunning so running Gs have an // M. mp.curg = gp gp.m = mp casgstatus(gp, _Grunnable, _Grunning) gp.waitsince = 0 gp.preempt = false gp.stackguard0 = gp.stack.lo + _StackGuard if !inheritTime { mp.p.ptr().schedtick++ } // Check whether the profiler needs to be turned on or off. hz := sched.profilehz if mp.profilehz != hz { setThreadCPUProfiler(hz) } if trace.enabled { // GoSysExit has to happen when we have a P, but before GoStart. // So we emit it here. if gp.syscallsp != 0 && gp.sysblocktraced { traceGoSysExit(gp.sysexitticks) } traceGoStart() } gogo(&gp.sched) } - ↩︎
// Finds a runnable goroutine to execute. // Tries to steal from other P's, get g from local or global queue, poll network. // tryWakeP indicates that the returned goroutine is not normal (GC worker, trace // reader) so the caller should try to wake a P. func findRunnable() (gp *g, inheritTime, tryWakeP bool) { mp := getg().m // The conditions here and in handoffp must agree: if // findrunnable would return a G to run, handoffp must start // an M. top: pp := mp.p.ptr() if sched.gcwaiting.Load() { gcstopm() goto top } if pp.runSafePointFn != 0 { runSafePointFn() } // now and pollUntil are saved for work stealing later, // which may steal timers. It's important that between now // and then, nothing blocks, so these numbers remain mostly // relevant. now, pollUntil, _ := checkTimers(pp, 0) // Try to schedule the trace reader. if trace.enabled || trace.shutdown { gp := traceReader() if gp != nil { casgstatus(gp, _Gwaiting, _Grunnable) traceGoUnpark(gp, 0) return gp, false, true } } // Try to schedule a GC worker. if gcBlackenEnabled != 0 { gp, tnow := gcController.findRunnableGCWorker(pp, now) if gp != nil { return gp, false, true } now = tnow } // Check the global runnable queue once in a while to ensure fairness. // Otherwise two goroutines can completely occupy the local runqueue // by constantly respawning each other. if pp.schedtick%61 == 0 && sched.runqsize > 0 { lock(&sched.lock) gp := globrunqget(pp, 1) unlock(&sched.lock) if gp != nil { return gp, false, false } } // Wake up the finalizer G. if fingStatus.Load()&(fingWait|fingWake) == fingWait|fingWake { if gp := wakefing(); gp != nil { ready(gp, 0, true) } } if *cgo_yield != nil { asmcgocall(*cgo_yield, nil) } // local runq if gp, inheritTime := runqget(pp); gp != nil { return gp, inheritTime, false } // global runq if sched.runqsize != 0 { lock(&sched.lock) gp := globrunqget(pp, 0) unlock(&sched.lock) if gp != nil { return gp, false, false } } // Poll network. // This netpoll is only an optimization before we resort to stealing. // We can safely skip it if there are no waiters or a thread is blocked // in netpoll already. If there is any kind of logical race with that // blocked thread (e.g. it has already returned from netpoll, but does // not set lastpoll yet), this thread will do blocking netpoll below // anyway. if netpollinited() && netpollWaiters.Load() > 0 && sched.lastpoll.Load() != 0 { if list := netpoll(0); !list.empty() { // non-blocking gp := list.pop() injectglist(&list) casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } return gp, false, false } } // Spinning Ms: steal work from other Ps. // // Limit the number of spinning Ms to half the number of busy Ps. // This is necessary to prevent excessive CPU consumption when // GOMAXPROCS>>1 but the program parallelism is low. if mp.spinning || 2*sched.nmspinning.Load() < gomaxprocs-sched.npidle.Load() { if !mp.spinning { mp.becomeSpinning() } gp, inheritTime, tnow, w, newWork := stealWork(now) if gp != nil { // Successfully stole. return gp, inheritTime, false } if newWork { // There may be new timer or GC work; restart to // discover. goto top } now = tnow if w != 0 && (pollUntil == 0 || w < pollUntil) { // Earlier timer to wait for. pollUntil = w } } // We have nothing to do. // // If we're in the GC mark phase, can safely scan and blacken objects, // and have work to do, run idle-time marking rather than give up the P. if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() { node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop()) if node != nil { pp.gcMarkWorkerMode = gcMarkWorkerIdleMode gp := node.gp.ptr() casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } return gp, false, false } gcController.removeIdleMarkWorker() } // wasm only: // If a callback returned and no other goroutine is awake, // then wake event handler goroutine which pauses execution // until a callback was triggered. gp, otherReady := beforeIdle(now, pollUntil) if gp != nil { casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } return gp, false, false } if otherReady { goto top } // Before we drop our P, make a snapshot of the allp slice, // which can change underfoot once we no longer block // safe-points. We don't need to snapshot the contents because // everything up to cap(allp) is immutable. allpSnapshot := allp // Also snapshot masks. Value changes are OK, but we can't allow // len to change out from under us. idlepMaskSnapshot := idlepMask timerpMaskSnapshot := timerpMask // return P and block lock(&sched.lock) if sched.gcwaiting.Load() || pp.runSafePointFn != 0 { unlock(&sched.lock) goto top } if sched.runqsize != 0 { gp := globrunqget(pp, 0) unlock(&sched.lock) return gp, false, false } if !mp.spinning && sched.needspinning.Load() == 1 { // See "Delicate dance" comment below. mp.becomeSpinning() unlock(&sched.lock) goto top } if releasep() != pp { throw("findrunnable: wrong p") } now = pidleput(pp, now) unlock(&sched.lock) // Delicate dance: thread transitions from spinning to non-spinning // state, potentially concurrently with submission of new work. We must // drop nmspinning first and then check all sources again (with // #StoreLoad memory barrier in between). If we do it the other way // around, another thread can submit work after we've checked all // sources but before we drop nmspinning; as a result nobody will // unpark a thread to run the work. // // This applies to the following sources of work: // // * Goroutines added to a per-P run queue. // * New/modified-earlier timers on a per-P timer heap. // * Idle-priority GC work (barring golang.org/issue/19112). // // If we discover new work below, we need to restore m.spinning as a // signal for resetspinning to unpark a new worker thread (because // there can be more than one starving goroutine). // // However, if after discovering new work we also observe no idle Ps // (either here or in resetspinning), we have a problem. We may be // racing with a non-spinning M in the block above, having found no // work and preparing to release its P and park. Allowing that P to go // idle will result in loss of work conservation (idle P while there is // runnable work). This could result in complete deadlock in the // unlikely event that we discover new work (from netpoll) right as we // are racing with _all_ other Ps going idle. // // We use sched.needspinning to synchronize with non-spinning Ms going // idle. If needspinning is set when they are about to drop their P, // they abort the drop and instead become a new spinning M on our // behalf. If we are not racing and the system is truly fully loaded // then no spinning threads are required, and the next thread to // naturally become spinning will clear the flag. // // Also see "Worker thread parking/unparking" comment at the top of the // file. wasSpinning := mp.spinning if mp.spinning { mp.spinning = false if sched.nmspinning.Add(-1) < 0 { throw("findrunnable: negative nmspinning") } // Note the for correctness, only the last M transitioning from // spinning to non-spinning must perform these rechecks to // ensure no missed work. However, the runtime has some cases // of transient increments of nmspinning that are decremented // without going through this path, so we must be conservative // and perform the check on all spinning Ms. // // See https://go.dev/issue/43997. // Check all runqueues once again. pp := checkRunqsNoP(allpSnapshot, idlepMaskSnapshot) if pp != nil { acquirep(pp) mp.becomeSpinning() goto top } // Check for idle-priority GC work again. pp, gp := checkIdleGCNoP() if pp != nil { acquirep(pp) mp.becomeSpinning() // Run the idle worker. pp.gcMarkWorkerMode = gcMarkWorkerIdleMode casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } return gp, false, false } // Finally, check for timer creation or expiry concurrently with // transitioning from spinning to non-spinning. // // Note that we cannot use checkTimers here because it calls // adjusttimers which may need to allocate memory, and that isn't // allowed when we don't have an active P. pollUntil = checkTimersNoP(allpSnapshot, timerpMaskSnapshot, pollUntil) } // Poll network until next timer. if netpollinited() && (netpollWaiters.Load() > 0 || pollUntil != 0) && sched.lastpoll.Swap(0) != 0 { sched.pollUntil.Store(pollUntil) if mp.p != 0 { throw("findrunnable: netpoll with p") } if mp.spinning { throw("findrunnable: netpoll with spinning") } // Refresh now. now = nanotime() delay := int64(-1) if pollUntil != 0 { delay = pollUntil - now if delay < 0 { delay = 0 } } if faketime != 0 { // When using fake time, just poll. delay = 0 } list := netpoll(delay) // block until new work is available sched.pollUntil.Store(0) sched.lastpoll.Store(now) if faketime != 0 && list.empty() { // Using fake time and nothing is ready; stop M. // When all M's stop, checkdead will call timejump. stopm() goto top } lock(&sched.lock) pp, _ := pidleget(now) unlock(&sched.lock) if pp == nil { injectglist(&list) } else { acquirep(pp) if !list.empty() { gp := list.pop() injectglist(&list) casgstatus(gp, _Gwaiting, _Grunnable) if trace.enabled { traceGoUnpark(gp, 0) } return gp, false, false } if wasSpinning { mp.becomeSpinning() } goto top } } else if pollUntil != 0 && netpollinited() { pollerPollUntil := sched.pollUntil.Load() if pollerPollUntil == 0 || pollerPollUntil > pollUntil { netpollBreak() } } stopm() goto top } - ↩︎
// Stops the current m for stopTheWorld. // Returns when the world is restarted. func gcstopm() { gp := getg() if !sched.gcwaiting.Load() { throw("gcstopm: not waiting for gc") } if gp.m.spinning { gp.m.spinning = false // OK to just drop nmspinning here, // startTheWorld will unpark threads as necessary. if sched.nmspinning.Add(-1) < 0 { throw("gcstopm: negative nmspinning") } } pp := releasep() lock(&sched.lock) pp.status = _Pgcstop sched.stopwait-- if sched.stopwait == 0 { notewakeup(&sched.stopnote) } unlock(&sched.lock) stopm() } - ↩︎
// runSafePointFn runs the safe point function, if any, for this P. // This should be called like // // if getg().m.p.runSafePointFn != 0 { // runSafePointFn() // } // // runSafePointFn must be checked on any transition in to _Pidle or // _Psyscall to avoid a race where forEachP sees that the P is running // just before the P goes into _Pidle/_Psyscall and neither forEachP // nor the P run the safe-point function. func runSafePointFn() { p := getg().m.p.ptr() // Resolve the race between forEachP running the safe-point // function on this P's behalf and this P running the // safe-point function directly. if !atomic.Cas(&p.runSafePointFn, 1, 0) { return } sched.safePointFn(p) lock(&sched.lock) sched.safePointWait-- if sched.safePointWait == 0 { notewakeup(&sched.safePointNote) } unlock(&sched.lock) } - ↩︎ ↩︎
// checkTimers runs any timers for the P that are ready. // If now is not 0 it is the current time. // It returns the passed time or the current time if now was passed as 0. // and the time when the next timer should run or 0 if there is no next timer, // and reports whether it ran any timers. // If the time when the next timer should run is not 0, // it is always larger than the returned time. // We pass now in and out to avoid extra calls of nanotime. // //go:yeswritebarrierrec func checkTimers(pp *p, now int64) (rnow, pollUntil int64, ran bool) { // If it's not yet time for the first timer, or the first adjusted // timer, then there is nothing to do. next := pp.timer0When.Load() nextAdj := pp.timerModifiedEarliest.Load() if next == 0 || (nextAdj != 0 && nextAdj < next) { next = nextAdj } if next == 0 { // No timers to run or adjust. return now, 0, false } if now == 0 { now = nanotime() } if now < next { // Next timer is not ready to run, but keep going // if we would clear deleted timers. // This corresponds to the condition below where // we decide whether to call clearDeletedTimers. if pp != getg().m.p.ptr() || int(pp.deletedTimers.Load()) <= int(pp.numTimers.Load()/4) { return now, next, false } } lock(&pp.timersLock) if len(pp.timers) > 0 { adjusttimers(pp, now) for len(pp.timers) > 0 { // Note that runtimer may temporarily unlock // pp.timersLock. if tw := runtimer(pp, now); tw != 0 { if tw > 0 { pollUntil = tw } break } ran = true } } // If this is the local P, and there are a lot of deleted timers, // clear them out. We only do this for the local P to reduce // lock contention on timersLock. if pp == getg().m.p.ptr() && int(pp.deletedTimers.Load()) > len(pp.timers)/4 { clearDeletedTimers(pp) } unlock(&pp.timersLock) return now, pollUntil, ran } - ↩︎
// Check the global runnable queue once in a while to ensure fairness. // Otherwise two goroutines can completely occupy the local runqueue // by constantly respawning each other. if pp.schedtick%61 == 0 && sched.runqsize > 0 { lock(&sched.lock) gp := globrunqget(pp, 1) unlock(&sched.lock) if gp != nil { return gp, false, false } } - ↩︎
// Get g from local runnable queue. // If inheritTime is true, gp should inherit the remaining time in the // current time slice. Otherwise, it should start a new time slice. // Executed only by the owner P. func runqget(pp *p) (gp *g, inheritTime bool) { // If there's a runnext, it's the next G to run. next := pp.runnext // If the runnext is non-0 and the CAS fails, it could only have been stolen by another P, // because other Ps can race to set runnext to 0, but only the current P can set it to non-0. // Hence, there's no need to retry this CAS if it fails. if next != 0 && pp.runnext.cas(next, 0) { return next.ptr(), true } for { h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with other consumers t := pp.runqtail if t == h { return nil, false } gp := pp.runq[h%uint32(len(pp.runq))].ptr() if atomic.CasRel(&pp.runqhead, h, h+1) { // cas-release, commits consume return gp, false } } } - ↩︎
// Spinning Ms: steal work from other Ps. // // Limit the number of spinning Ms to half the number of busy Ps. // This is necessary to prevent excessive CPU consumption when // GOMAXPROCS>>1 but the program parallelism is low. if mp.spinning || 2*sched.nmspinning.Load() < gomaxprocs-sched.npidle.Load() { ... } - ↩︎
if !mp.spinning { mp.becomeSpinning() } gp, inheritTime, tnow, w, newWork := stealWork(now) if gp != nil { // Successfully stole. return gp, inheritTime, false } if newWork { // There may be new timer or GC work; restart to // discover. goto top } now = tnow if w != 0 && (pollUntil == 0 || w < pollUntil) { // Earlier timer to wait for. pollUntil = w } - ↩︎
// return P and block lock(&sched.lock) if sched.gcwaiting.Load() || pp.runSafePointFn != 0 { unlock(&sched.lock) goto top } if sched.runqsize != 0 { gp := globrunqget(pp, 0) unlock(&sched.lock) return gp, false, false } if !mp.spinning && sched.needspinning.Load() == 1 { // See "Delicate dance" comment below. mp.becomeSpinning() unlock(&sched.lock) goto top } if releasep() != pp { throw("findrunnable: wrong p") } now = pidleput(pp, now) unlock(&sched.lock) - ↩︎
// Try get a batch of G's from the global runnable queue. // sched.lock must be held. func globrunqget(pp *p, max int32) *g { assertLockHeld(&sched.lock) if sched.runqsize == 0 { return nil } n := sched.runqsize/gomaxprocs + 1 if n > sched.runqsize { n = sched.runqsize } if max > 0 && n > max { n = max } if n > int32(len(pp.runq))/2 { n = int32(len(pp.runq)) / 2 } sched.runqsize -= n gp := sched.runq.pop() n-- for ; n > 0; n-- { gp1 := sched.runq.pop() runqput(pp, gp1, false) } return gp } - ↩︎
// assertLockHeld throws if l is not held by the caller. // // nosplit to ensure it can be called in as many contexts as possible. // //go:nosplit func assertLockHeld(l *mutex) { gp := getg() held := checkLockHeld(gp, l) if held { return } // Crash from system stack to avoid splits that may cause // additional issues. systemstack(func() { printlock() print("caller requires lock ", l, " (rank ", l.rank.String(), "), holding:\n") printHeldLocks(gp) throw("not holding required lock!") }) } - ↩︎
// stealWork attempts to steal a runnable goroutine or timer from any P. // // If newWork is true, new work may have been readied. // // If now is not 0 it is the current time. stealWork returns the passed time or // the current time if now was passed as 0. func stealWork(now int64) (gp *g, inheritTime bool, rnow, pollUntil int64, newWork bool) { pp := getg().m.p.ptr() ranTimer := false const stealTries = 4 for i := 0; i < stealTries; i++ { stealTimersOrRunNextG := i == stealTries-1 for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() { if sched.gcwaiting.Load() { // GC work may be available. return nil, false, now, pollUntil, true } p2 := allp[enum.position()] if pp == p2 { continue } // Steal timers from p2. This call to checkTimers is the only place // where we might hold a lock on a different P's timers. We do this // once on the last pass before checking runnext because stealing // from the other P's runnext should be the last resort, so if there // are timers to steal do that first. // // We only check timers on one of the stealing iterations because // the time stored in now doesn't change in this loop and checking // the timers for each P more than once with the same value of now // is probably a waste of time. // // timerpMask tells us whether the P may have timers at all. If it // can't, no need to check at all. if stealTimersOrRunNextG && timerpMask.read(enum.position()) { tnow, w, ran := checkTimers(p2, now) now = tnow if w != 0 && (pollUntil == 0 || w < pollUntil) { pollUntil = w } if ran { // Running the timers may have // made an arbitrary number of G's // ready and added them to this P's // local run queue. That invalidates // the assumption of runqsteal // that it always has room to add // stolen G's. So check now if there // is a local G to run. if gp, inheritTime := runqget(pp); gp != nil { return gp, inheritTime, now, pollUntil, ranTimer } ranTimer = true } } // Don't bother to attempt to steal if p2 is idle. if !idlepMask.read(enum.position()) { if gp := runqsteal(pp, p2, stealTimersOrRunNextG); gp != nil { return gp, false, now, pollUntil, ranTimer } } } } // No goroutines found to steal. Regardless, running a timer may have // made some goroutine ready that we missed. Indicate the next timer to // wait for. return nil, false, now, pollUntil, ranTimer } - ↩︎
// Don't bother to attempt to steal if p2 is idle. if !idlepMask.read(enum.position()) { if gp := runqsteal(pp, p2, stealTimersOrRunNextG); gp != nil { return gp, false, now, pollUntil, ranTimer } } - ↩︎
// Steal half of elements from local runnable queue of p2 // and put onto local runnable queue of p. // Returns one of the stolen elements (or nil if failed). func runqsteal(pp, p2 *p, stealRunNextG bool) *g { t := pp.runqtail n := runqgrab(p2, &pp.runq, t, stealRunNextG) if n == 0 { return nil } n-- gp := pp.runq[(t+n)%uint32(len(pp.runq))].ptr() if n == 0 { return gp } h := atomic.LoadAcq(&pp.runqhead) // load-acquire, synchronize with consumers if t-h+n >= uint32(len(pp.runq)) { throw("runqsteal: runq overflow") } atomic.StoreRel(&pp.runqtail, t+n) // store-release, makes the item available for consumption return gp } - ↩︎
// Grabs a batch of goroutines from _p_'s runnable queue into batch. // Batch is a ring buffer starting at batchHead. // Returns number of grabbed goroutines. // Can be executed by any P. func runqgrab(_p_ *p, batch *[256]guintptr, batchHead uint32, stealRunNextG bool) uint32 { for { h := atomic.LoadAcq(&_p_.runqhead) // load-acquire, synchronize with other consumers t := atomic.LoadAcq(&_p_.runqtail) // load-acquire, synchronize with the producer n := t - h n = n - n/2 if n == 0 { if stealRunNextG { // Try to steal from _p_.runnext. if next := _p_.runnext; next != 0 { if _p_.status == _Prunning { // Sleep to ensure that _p_ isn't about to run the g // we are about to steal. // The important use case here is when the g running // on _p_ ready()s another g and then almost // immediately blocks. Instead of stealing runnext // in this window, back off to give _p_ a chance to // schedule runnext. This will avoid thrashing gs // between different Ps. // A sync chan send/recv takes ~50ns as of time of // writing, so 3us gives ~50x overshoot. if GOOS != "windows" && GOOS != "openbsd" && GOOS != "netbsd" { usleep(3) } else { // On some platforms system timer granularity is // 1-15ms, which is way too much for this // optimization. So just yield. osyield() } } if !_p_.runnext.cas(next, 0) { continue } batch[batchHead%uint32(len(batch))] = next return 1 } } return 0 } if n > uint32(len(_p_.runq)/2) { // read inconsistent h and t continue } for i := uint32(0); i < n; i++ { g := _p_.runq[(h+i)%uint32(len(_p_.runq))] batch[(batchHead+i)%uint32(len(batch))] = g } if atomic.CasRel(&_p_.runqhead, h, h+n) { // cas-release, commits consume return n } } } - ↩︎ ↩︎
// func gogo(buf *gobuf) // restore state from Gobuf; longjmp TEXT runtime·gogo(SB), NOSPLIT, $0-8 MOVQ buf+0(FP), BX // gobuf MOVQ gobuf_g(BX), DX MOVQ 0(DX), CX // make sure g != nil JMP gogo<>(SB) TEXT gogo<>(SB), NOSPLIT, $0 get_tls(CX) MOVQ DX, g(CX) MOVQ DX, R14 // set the g register MOVQ gobuf_sp(BX), SP // restore SP MOVQ gobuf_ret(BX), AX MOVQ gobuf_ctxt(BX), DX MOVQ gobuf_bp(BX), BP MOVQ $0, gobuf_sp(BX) // clear to help garbage collector MOVQ $0, gobuf_ret(BX) MOVQ $0, gobuf_ctxt(BX) MOVQ $0, gobuf_bp(BX) MOVQ gobuf_pc(BX), BX JMP BX - ↩︎
// The top-most function running on a goroutine // returns to goexit+PCQuantum. TEXT runtime·goexit(SB),NOSPLIT|TOPFRAME|NOFRAME,$0-0 BYTE $0x90 // NOP CALL runtime·goexit1(SB) // does not return // traceback from goexit1 must hit code range of goexit BYTE $0x90 // NOP - ↩︎
// Finishes execution of the current goroutine. func goexit1() { if raceenabled { racegoend() } if traceEnabled() { traceGoEnd() } mcall(goexit0) } - ↩︎
// goexit continuation on g0. func goexit0(gp *g) { mp := getg().m pp := mp.p.ptr() casgstatus(gp, _Grunning, _Gdead) gcController.addScannableStack(pp, -int64(gp.stack.hi-gp.stack.lo)) if isSystemGoroutine(gp, false) { sched.ngsys.Add(-1) } gp.m = nil locked := gp.lockedm != 0 gp.lockedm = 0 mp.lockedg = 0 gp.preemptStop = false gp.paniconfault = false gp._defer = nil // should be true already but just in case. gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data. gp.writebuf = nil gp.waitreason = waitReasonZero gp.param = nil gp.labels = nil gp.timer = nil if gcBlackenEnabled != 0 && gp.gcAssistBytes > 0 { // Flush assist credit to the global pool. This gives // better information to pacing if the application is // rapidly creating an exiting goroutines. assistWorkPerByte := gcController.assistWorkPerByte.Load() scanCredit := int64(assistWorkPerByte * float64(gp.gcAssistBytes)) gcController.bgScanCredit.Add(scanCredit) gp.gcAssistBytes = 0 } dropg() if GOARCH == "wasm" { // no threads yet on wasm gfput(pp, gp) schedule() // never returns } if mp.lockedInt != 0 { print("invalid m->lockedInt = ", mp.lockedInt, "\n") throw("internal lockOSThread error") } gfput(pp, gp) if locked { // The goroutine may have locked this thread because // it put it in an unusual kernel state. Kill it // rather than returning it to the thread pool. // Return to mstart, which will release the P and exit // the thread. if GOOS != "plan9" { // See golang.org/issue/22227. gogo(&mp.g0.sched) } else { // Clear lockedExt on plan9 since we may end up re-using // this thread. mp.lockedExt = 0 } } schedule() } - ↩︎
// Put on gfree list. // If local list is too long, transfer a batch to the global list. func gfput(pp *p, gp *g) { if readgstatus(gp) != _Gdead { throw("gfput: bad status (not Gdead)") } stksize := gp.stack.hi - gp.stack.lo if stksize != uintptr(startingStackSize) { // non-standard stack size - free it. stackfree(gp.stack) gp.stack.lo = 0 gp.stack.hi = 0 gp.stackguard0 = 0 } pp.gFree.push(gp) pp.gFree.n++ if pp.gFree.n >= 64 { var ( inc int32 stackQ gQueue noStackQ gQueue ) for pp.gFree.n >= 32 { gp := pp.gFree.pop() pp.gFree.n-- if gp.stack.lo == 0 { noStackQ.push(gp) } else { stackQ.push(gp) } inc++ } lock(&sched.gFree.lock) sched.gFree.noStack.pushAll(noStackQ) sched.gFree.stack.pushAll(stackQ) sched.gFree.n += inc unlock(&sched.gFree.lock) } } - ↩︎
// func mcall(fn func(*g)) // Switch to m->g0's stack, call fn(g). // Fn must never return. It should gogo(&g->sched) // to keep running g. TEXT runtime·mcall<ABIInternal>(SB), NOSPLIT, $0-8 MOVQ AX, DX // DX = fn // save state in g->sched MOVQ 0(SP), BX // caller's PC MOVQ BX, (g_sched+gobuf_pc)(R14) LEAQ fn+0(FP), BX // caller's SP MOVQ BX, (g_sched+gobuf_sp)(R14) MOVQ BP, (g_sched+gobuf_bp)(R14) // switch to m->g0 & its stack, call fn MOVQ g_m(R14), BX MOVQ m_g0(BX), SI // SI = g.m.g0 CMPQ SI, R14 // if g == m->g0 call badmcall JNE goodm JMP runtime·badmcall(SB) goodm: MOVQ R14, AX // AX (and arg 0) = g MOVQ SI, R14 // g = g.m.g0 get_tls(CX) // Set G in TLS MOVQ R14, g(CX) MOVQ (g_sched+gobuf_sp)(R14), SP // sp = g0.sched.sp PUSHQ AX // open up space for fn's arg spill slot MOVQ 0(DX), R12 CALL R12 // fn(g) POPQ AX JMP runtime·badmcall2(SB) RET





