MySQL8 手册
修改密码
mysql> show databases;
mysql> use mysql;
mysql> ALTER USER '用户名'@'localhost' IDENTIFIED WITH mysql_native_password BY '新密码';
mysql> flush privileges; --刷新MySQL的系统权限相关表
mysql> exit;
KB
执行一条 SQL 查询语句,期间发生了什么?
Details
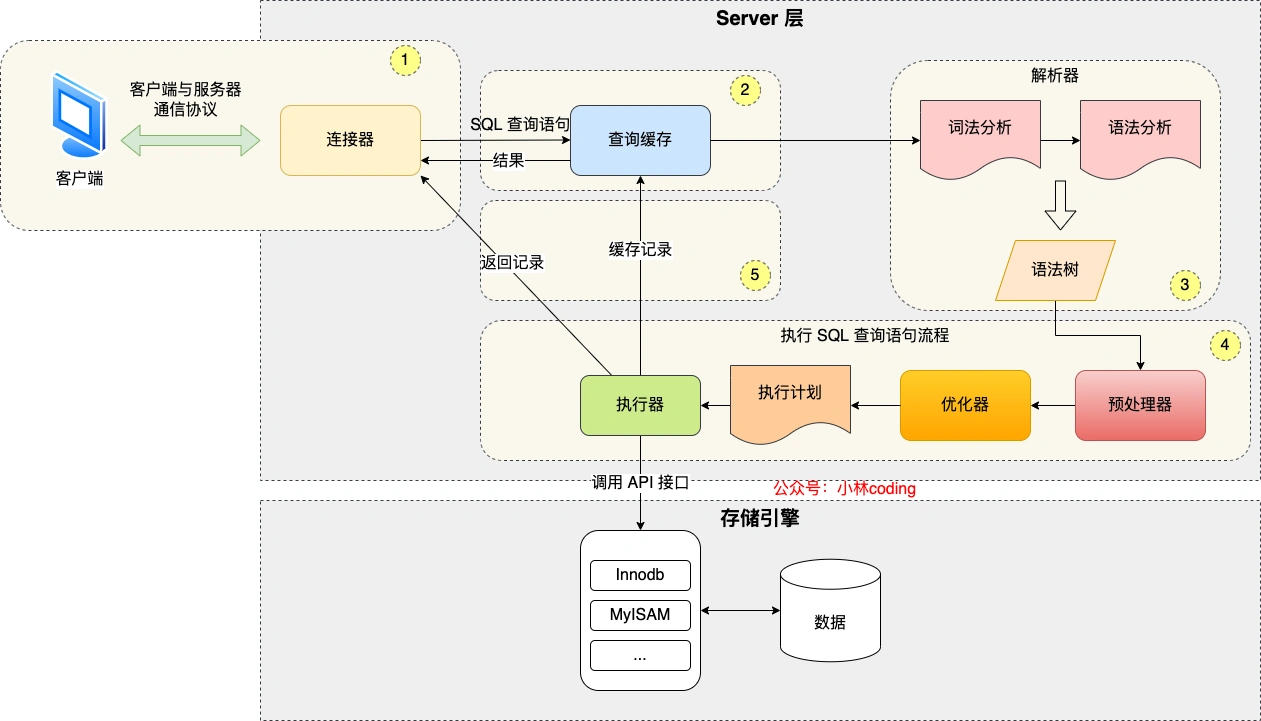
- 连接器:建立连接,管理连接、校验用户身份;
- 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块;
- 解析 SQL:通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型;
- 执行 SQL
- 预处理阶段:检查表或字段是否存在;将 select _ 中的 _ 符号扩展为表上的所有列。
- 优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划;
- 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端;
MySQL 一行记录是怎么存储的?
Details
表空间由段(segment)、区(extent)、页(page)、行(row)组成,InnoDB存储引擎的逻辑存储结构大致如下图:
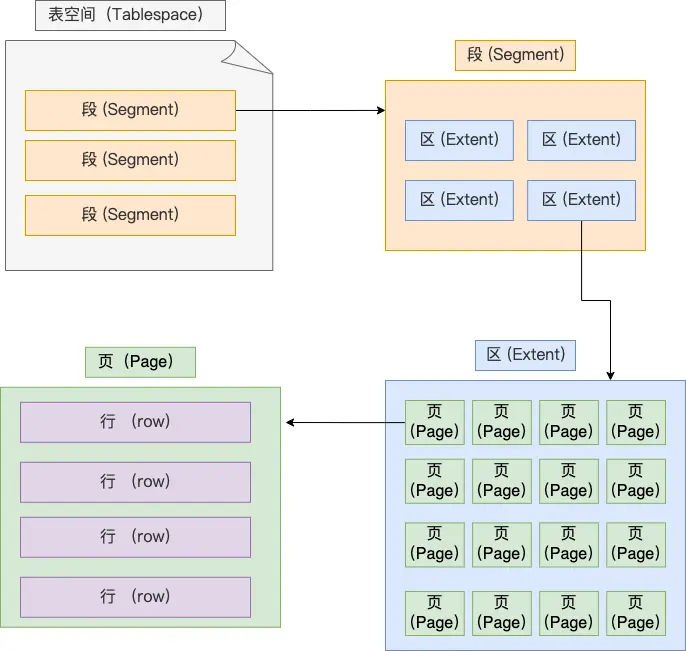
- 行:数据库表中的记录都是按行(row)进行存放的,每行记录根据不同的行格式,有不同的存储结构
- 页:记录是按照行来存储的,但是数据库的读取并不以「行」为单位,否则一次读取(也就是一次 I/O 操作)只能处理一行数据,效率会非常低。因此,InnoDB 的数据是按「页」为单位来读写的,也就是说,当需要读一条记录的时候,并不是将这个行记录从磁盘读出来,而是以页为单位,将其整体读入内存。
- 区:我们知道 InnoDB 存储引擎是用 B+ 树来组织数据的。B+ 树中每一层都是通过双向链表连接起来的,如果是以页为单位来分配存储空间,那么链表中相邻的两个页之间的物理位置并不是连续的,可能离得非常远,那么磁盘查询时就会有大量的随机I/O,随机 I/O 是非常慢的。解决这个问题也很简单,就是让链表中相邻的页的物理位置也相邻,这样就可以使用顺序 I/O 了,那么在范围查询(扫描叶子节点)的时候性能就会很高。在表中数据量大的时候,为某个索引分配空间的时候就不再按照页为单位分配了,而是按照区(extent)为单位分配。每个区的大小为 1MB,对于 16KB 的页来说,连续的 64 个页会被划为一个区,这样就使得链表中相邻的页的物理位置也相邻,就能使用顺序 I/O 了。
- 段:表空间是由各个段(segment)组成的,段是由多个区(extent)组成的。段一般分为数据段、索引段和回滚段等。
- 索引段:存放 B + 树的非叶子节点的区的集合;
- 数据段:存放 B + 树的叶子节点的区的集合;
- 回滚段:存放的是回滚数据的区的集合,之前讲事务隔离 (opens new window)的时候就介绍到了 MVCC 利用了回滚段实现了多版本查询数据。
行格式,就是一条记录的存储结构。
InnoDB 提供了 4 种行格式,分别是 Redundant、Compact、Dynamic和 Compressed 行格式。
COMPACT 行格式长什么样?
Details
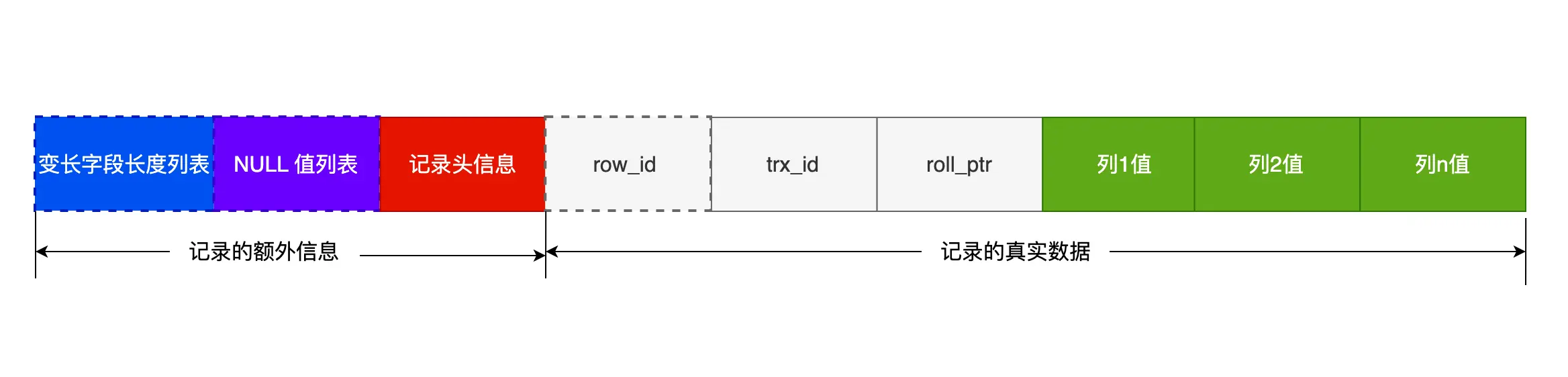
可以看到,一条完整的记录分为「记录的额外信息」和「记录的真实数据」两个部分。
记录的额外信息包含 3 个部分:变长字段长度列表、NULL 值列表、记录头信息。
行溢出后,MySQL 是怎么处理的?
从数据页的角度看 B+ 树 https://xiaolincoding.com/mysql/index/page.html 为什么 MySQL 采用 B+ 树作为索引? MySQL 单表不要超过 2000W 行,靠谱吗? 索引失效有哪些? MySQL 使用 like “%x“,索引一定会失效吗? count(*) 和 count(1) 有什么区别?哪个性能最好? 事务隔离级别是怎么实现的? MySQL 可重复读隔离级别,完全解决幻读了吗? MySQL 有哪些锁? MySQL 是怎么加锁的? update 没加索引会锁全表? MySQL 记录锁+间隙锁可以防止删除操作而导致的幻读吗? MySQL 死锁了,怎么办? 字节面试:加了什么锁,导致死锁的? undo log、redo log、binlog 有什么用? 揭开 Buffer_Pool 的面纱
grammar
- create database xxx
- show databases
- use database
插入
insert into 表名 (column_name1, column_name2, …) values (value1, value2, …)
查询
select[distinct][concat (col1,":",col2) as col] selection_list // 选择的列 from 数据表名 where primary_constraint // 查询条件 group by grouping_cols // 分组 order by sorting_cols // 排序 having secondary_constraint // 查询的第二条件 limit count
where
- =
=
- <=
- <
- != 或者 <>
- IS NULL
- IS NOT NULL
- BETWEEN AND
- IN
- NOT IN
- LIKE % _
- NOT LIKE
- REGEXP
update
update 表名 set col_name1=new_value1, col_name2=new_value2, … where condition
delete
函数
- SUM
- AVG
niuke
Reference
ALTER USER 'root'@'localhost' IDENTIFIED WITH 'mysql*native_password' BY 'your_password'; GRANT ALL PRIVILEGES ON *._ TO 'root'@'%' IDENTIFIED BY 'your_password'; // 8 失败 FLUSH PRIVILEGES;
update user set host='%' where user='root';
GRANT ALL ON . TO 'root'@'%';
ALTER USER 'root'@'%' IDENTIFIED WITH 'mysql_native_password' BY 'xxx';
执行一条 select 语句,期间发生了什么?
- 连接器
- 查询缓存
- 解析 SQL
- 执行 SQL
- prepare 阶段,也就是预处理阶段;
- optimize 阶段,也就是优化阶段;
- execute 阶段,也就是执行阶段; :::
MySQL 一行记录是怎么存储的?
索引
索引的分类
- 按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
- 按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
- 按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
- 按「字段个数」分类:单列索引、联合索引。
什么时候适用索引?
- 字段有唯一性限制的,比如商品编码;
- 经常用于 WHERE 查询条件的字段,这样能够提高整个表的查询速度,如果查询条件不是一个字段,可以建立联合索引。
- 经常用于 GROUP BY 和 ORDER BY 的字段,这样在查询的时候就不需要再去做一次排序了,因为我们都已经知道了建立索引之后在 B+Tree 中的记录都是排序好的。
什么时候不需要创建索引?
- WHERE 条件,GROUP BY,ORDER BY 里用不到的字段,索引的价值是快速定位,如果起不到定位的字段通常是不需要创建索引的,因为索引是会占用物理空间的。
- 字段中存在大量重复数据,不需要创建索引,比如性别字段,只有男女,如果数据库表中,男女的记录分布均匀,那么无论搜索哪个值都可能得到一半的数据。在这些情况下,还不如不要索引,因为 MySQL 还有一个查询优化器,查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。
- 表数据太少的时候,不需要创建索引;
- 经常更新的字段不用创建索引,比如不要对电商项目的用户余额建立索引,因为索引字段频繁修改,由于要维护 B+Tree的有序性,那么就需要频繁的重建索引,这个过程是会影响数据库性能的。
有什么优化索引的方法?
- 前缀索引优化;
- 覆盖索引优化;
- 主键索引最好是自增的;
- 防止索引失效;
- All(全表扫描);
- index(全索引扫描);
- range(索引范围扫描);
- ref(非唯一索引扫描);
- eq_ref(唯一索引扫描);
- const(结果只有一条的主键或唯一索引扫描)
- 冗余字段
索引失效有哪些?
- 对索引使用左或者左右模糊匹配
- 对索引使用函数
- 对索引进行表达式计算
- 对索引隐式类型转换
- 联合索引非最左匹配
- WHERE 子句中的 OR
事务
InnoDB 引擎通过什么技术来保证事务的这四个特性的呢?
- 持久性是通过 redo log (重做日志)来保证的;
- 原子性是通过 undo log(回滚日志) 来保证的;
- 隔离性是通过 MVCC(多版本并发控制) 或锁机制来保证的;
- 一致性则是通过持久性+原子性+隔离性来保证;
Read View 在 MVCC 里如何工作的?
- m_ids :指的是在创建 Read View 时,当前数据库中「活跃事务」的事务 id 列表,注意是一个列表,“活跃事务”指的就是,启动了但还没提交的事务。
- min_trx_id :指的是在创建 Read View 时,当前数据库中「活跃事务」中事务 id 最小的事务,也就是 m_ids 的最小值。
- max_trx_id :这个并不是 m_ids 的最大值,而是创建 Read View 时当前数据库中应该给下一个事务的 id 值,也就是全局事务中最大的事务 id 值 + 1;
- creator_trx_id :指的是创建该 Read View 的事务的事务 id
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
- 如果记录的 trx_id 值小于 Read View 中的 min_trx_id 值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。
- 如果记录的 trx_id 值大于等于 Read View 中的 max_trx_id 值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 值在 Read View 的 min_trx_id 和 max_trx_id 之间,需要判断 trx_id 是否在 m_ids 列表中:
- 如果记录的 trx_id 在 m_ids 列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。
- 如果记录的 trx_id 不在 m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
读提交是如何工作的?
读提交隔离级别是在每次读取数据时,都会生成一个新的 Read View。
可重复读是如何工作的?
可重复读隔离级别是启动事务时生成一个 Read View,然后整个事务期间都在用这个 Read View。
避免幻读现象
- 针对快照读(普通 select 语句),是通过 MVCC 方式解决了幻读,因为可重复读隔离级别下,事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,即使中途有其他事务插入了一条数据,是查询不出来这条数据的,所以就很好了避免幻读问题。
- 针对当前读(select … for update 等语句),是通过 next-key lock(记录锁+间隙锁)方式解决了幻读,因为当执行 select … for update 语句的时候,会加上 next-key lock,如果有其他事务在 next-key lock 锁范围内插入了一条记录,那么这个插入语句就会被阻塞,无法成功插入,所以就很好了避免幻读问题。
快照读是如何避免幻读的?
可重复读隔离级是由 MVCC(多版本并发控制)实现的,实现的方式是开始事务后(执行 begin 语句后),在执行第一个查询语句后,会创建一个 Read View,后续的查询语句利用这个 Read View,通过这个 Read View 就可以在 undo log 版本链找到事务开始时的数据,所以事务过程中每次查询的数据都是一样的,即使中途有其他事务插入了新纪录,是查询不出来这条数据的,所以就很好了避免幻读问题。
当前读是如何避免幻读的?
除了普通查询是快照读,其他都是当前读,通过 next-key lock(记录锁+间隙锁)方式解决了幻读。
锁
MySQL 有哪些锁?
- 全局锁
- 表级锁
- 表锁
- 元数据锁
- 对一张表进行 CRUD 操作时,加的是 MDL 读锁
- 对一张表做结构变更操作的时候,加的是 MDL 写锁
- 意向锁
- 意向共享锁和意向独占锁是表级锁,不会和行级的共享锁和独占锁发生冲突,而且意向锁之间也不会发生冲突,只会和共享表锁(lock tables … read)和独占表锁(lock tables … write)发生冲突。意向锁的目的是为了快速判断表里是否有记录被加锁。如果没有「意向锁」,那么加「独占表锁」时,就需要遍历表里所有记录,查看是否有记录存在独占锁,这样效率会很慢。
- AUTO-INC 锁
- 行级锁
- 记录锁
- 间隙锁 只存在于可重复读隔离级别,目的是为了解决可重复读隔离级别下幻读的现象。
- 临键锁
- 插入意向锁 :::
有什么命令可以分析加了什么锁?
select * from performance_schema.data_locks\G
MySQL 是怎么加行级锁的?
日志
- undo log
- redo log
- 为什么需要两阶段提交?
其它
- MySQL 的存储引擎了解的有哪些
- InnoDB、MyISAM、Memory
- 分布式的 cap 理论
- MySQL 和 MongoDB 区别
- MySQL b+ 树索引和 hash 索引的区别
- sql 语句发现运行慢,如何优化
- 前缀索引优化
- 覆盖索引优化
- 主键索引最好是自增的
- 防止索引失效
- 你怎么知道它(一条 SQL 语句)使用没索引呢?(SHOW INDEX / EXPLAN)
- key key_len
- 向数据库里读写数据的流程是什么样子?
- 连接器:建立连接,管理连接、校验用户身份
- 查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行。MySQL 8.0 已删除该模块
- 解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型
- 执行 SQL
- 预处理阶段:检查表或字段是否存在;将
select *中的 * 符号扩展为表上的所有列 - 优化阶段:基于查询成本的考虑,选择查询成本最小的执行计划
- 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端
- 预处理阶段:检查表或字段是否存在;将
- 讲讲 MySQL MVCC
- Read View 中四个字段:creator_trx_id、m_ids、min_trx_id、max_trx_id
- 聚簇索引记录中两个跟事务有关的隐藏列:trx_id、roll_pointer
- 通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)
- 什么是幻读?
- 了解覆盖索引吗?什么时候用覆盖索引?
- query 的所有字段在二级索引的 B+Tree 上都能找到记录不需要再通过聚簇索引执行回表操作
- MySQL 的 ACID
- 事务特性:原子性(undo log 回滚日志)、一致性(持久性+原子性+隔离性)、隔离性(MVCC)、持久性(redo/undo log)
- 并行事务问题:脏读、不可重复度、幻读
- 隔离级别:读未提交、读提交、可重复读、串行化
高性能数据库优化实战经验
- 打破范式设计,冗余少量字段方便查询,需要注意源表和冗余表保证同一事务写。
- 关联关系在业务层面约束,不依赖数据库外键
- 字段拓展性,如模板信息这种结构不清晰的字段使用json类型,json检索的问题我的想法是少量key使用虚拟列并建立索引,多条件检索直接异构es
- 冷热分离,源表拆分成多张表,可以把频繁变更的字段放在主表,使用率较低的放在副表,判断依据可以是创建时间、业务域
- 服务拆分在分片字段选择上尽量考虑使用本地事务,让同业务的不同sql命中同一个分表,以避免使用分布式事务
- 尽量使用单表维度sql,原因:join性能差,后期分库分表更方便,前瞻性设计要考虑使用哪种ID主键策略





